Universal Instance Perception as Object Discovery and Retrieval
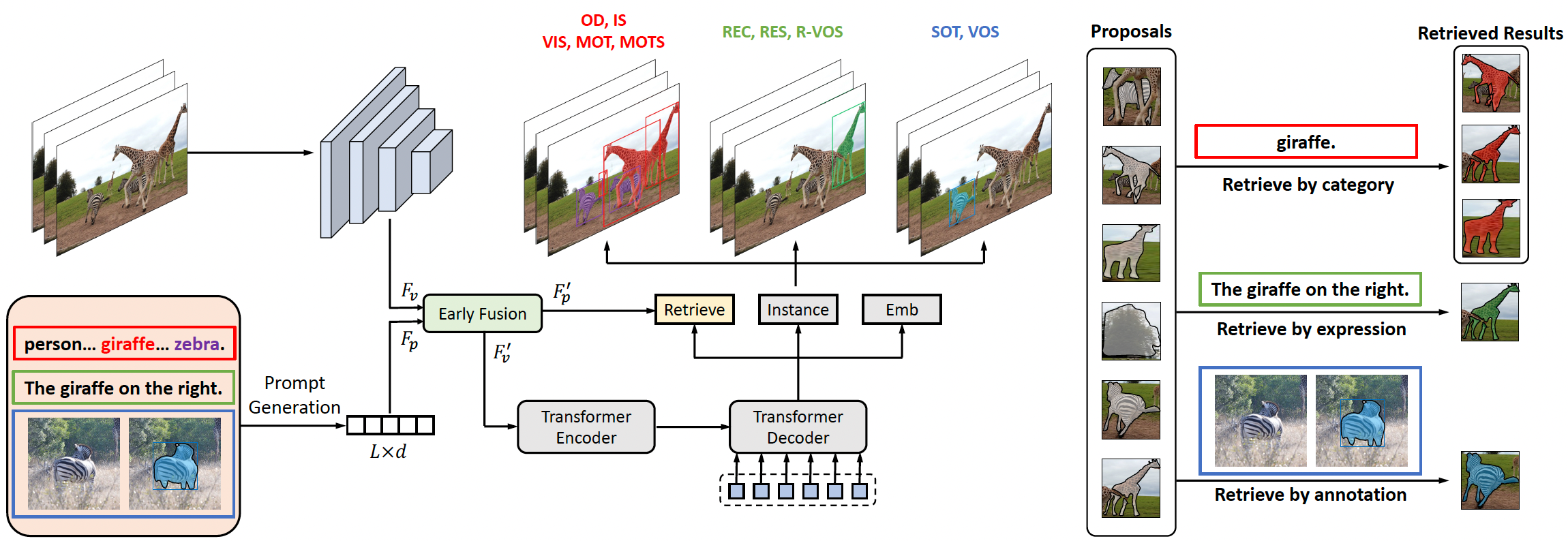
All instance perception tasks aim at finding certain objects specified by some queries such as category names, language expressions, and target annotations, but this complete field has been split into multiple independent subtasks. In this work, we present a universal instance perception model of the next generation, termed UNINEXT. UNINEXT reformulates diverse instance perception tasks into a unified object discovery and retrieval paradigm and can flexibly perceive different types of objects by simply changing the input prompts. This unified formulation brings the following benefits: (1) enormous data from different tasks and label vocabularies can be exploited for jointly training general instance-level representations, which is especially beneficial for tasks lacking in training data. (2) the unified model is parameter-efficient and can save redundant computation when handling multiple tasks simultaneously. UNINEXT shows superior performance on 20 challenging benchmarks from 10 instance-level tasks including classical image-level tasks (object detection and instance segmentation), vision-and-language tasks (referring expression comprehension and segmentation), and six video-level object tracking tasks. Code is available at https://github.com/MasterBin-IIAU/UNINEXT.
PDF Abstract CVPR 2023 PDF CVPR 2023 AbstractCode

Tasks
 Described Object Detection
Generalized Referring Expression Comprehension
Described Object Detection
Generalized Referring Expression Comprehension
 Instance Segmentation
Instance Segmentation
 Multi-Object Tracking and Segmentation
Multiple Object Tracking
Object
object-detection
Multi-Object Tracking and Segmentation
Multiple Object Tracking
Object
object-detection
 Object Detection
Object Discovery
Object Detection
Object Discovery
 Object Tracking
Referring Expression
Referring Expression Comprehension
Object Tracking
Referring Expression
Referring Expression Comprehension
 Referring Expression Segmentation
Referring Video Object Segmentation
Retrieval
Referring Expression Segmentation
Referring Video Object Segmentation
Retrieval
 Semantic Segmentation
Semantic Segmentation
 Video Instance Segmentation
Visual Object Tracking
Visual Tracking
Zero Shot Segmentation
Video Instance Segmentation
Visual Object Tracking
Visual Tracking
Zero Shot Segmentation
 MS COCO
MS COCO
 BDD100K
BDD100K
 RefCOCO
RefCOCO
 DAVIS 2017
DAVIS 2017
 LaSOT
LaSOT
 TrackingNet
TrackingNet
 YouTube-VOS 2018
YouTube-VOS 2018
 YouTube-VIS 2019
YouTube-VIS 2019
 Referring Expressions for DAVIS 2016 & 2017
Referring Expressions for DAVIS 2016 & 2017
 OVIS
OVIS
 TNL2K
TNL2K
 Refer-YouTube-VOS
Refer-YouTube-VOS
 gRefCOCO
gRefCOCO
 Segmentation in the Wild
Segmentation in the Wild
 Description Detection Dataset
Description Detection Dataset
Results from the Paper
 Ranked #1 on
Referring Expression Segmentation
on RefCoCo val
(using extra training data)
Ranked #1 on
Referring Expression Segmentation
on RefCoCo val
(using extra training data)
