Unsupervised Semantic Segmentation by Contrasting Object Mask Proposals
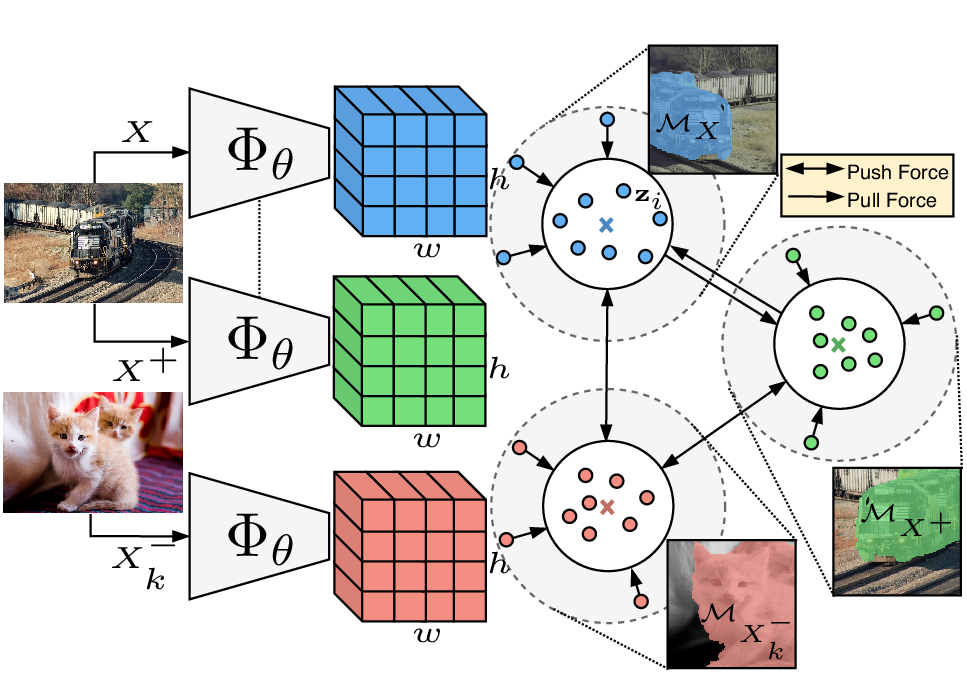
Being able to learn dense semantic representations of images without supervision is an important problem in computer vision. However, despite its significance, this problem remains rather unexplored, with a few exceptions that considered unsupervised semantic segmentation on small-scale datasets with a narrow visual domain. In this paper, we make a first attempt to tackle the problem on datasets that have been traditionally utilized for the supervised case. To achieve this, we introduce a two-step framework that adopts a predetermined mid-level prior in a contrastive optimization objective to learn pixel embeddings. This marks a large deviation from existing works that relied on proxy tasks or end-to-end clustering. Additionally, we argue about the importance of having a prior that contains information about objects, or their parts, and discuss several possibilities to obtain such a prior in an unsupervised manner. Experimental evaluation shows that our method comes with key advantages over existing works. First, the learned pixel embeddings can be directly clustered in semantic groups using K-Means on PASCAL. Under the fully unsupervised setting, there is no precedent in solving the semantic segmentation task on such a challenging benchmark. Second, our representations can improve over strong baselines when transferred to new datasets, e.g. COCO and DAVIS. The code is available.
PDF Abstract ICCV 2021 PDF ICCV 2021 Abstract




 MS COCO
MS COCO
 DAVIS
DAVIS
 COCO-Stuff
COCO-Stuff
 DUTS
DUTS
 DAVIS 2016
DAVIS 2016
 ImageNet-S
ImageNet-S

