ViTAS: Vision Transformer Architecture Search
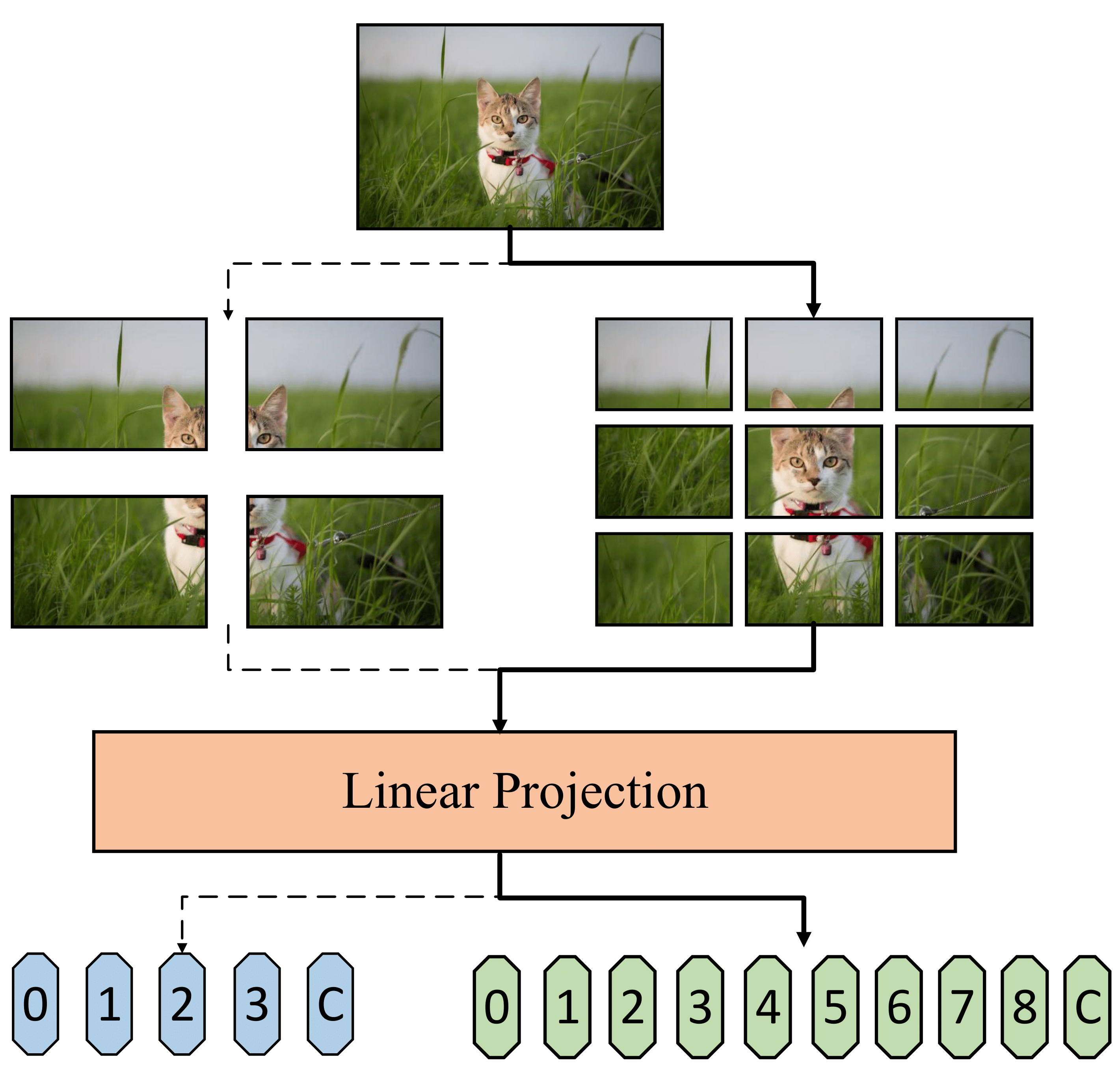
Vision transformers (ViTs) inherited the success of NLP but their structures have not been sufficiently investigated and optimized for visual tasks. One of the simplest solutions is to directly search the optimal one via the widely used neural architecture search (NAS) in CNNs. However, we empirically find this straightforward adaptation would encounter catastrophic failures and be frustratingly unstable for the training of superformer. In this paper, we argue that since ViTs mainly operate on token embeddings with little inductive bias, imbalance of channels for different architectures would worsen the weight-sharing assumption and cause the training instability as a result. Therefore, we develop a new cyclic weight-sharing mechanism for token embeddings of the ViTs, which enables each channel could more evenly contribute to all candidate architectures. Besides, we also propose identity shifting to alleviate the many-to-one issue in superformer and leverage weak augmentation and regularization techniques for more steady training empirically. Based on these, our proposed method, ViTAS, has achieved significant superiority in both DeiT- and Twins-based ViTs. For example, with only $1.4$G FLOPs budget, our searched architecture has $3.3\%$ ImageNet-$1$k accuracy than the baseline DeiT. With $3.0$G FLOPs, our results achieve $82.0\%$ accuracy on ImageNet-$1$k, and $45.9\%$ mAP on COCO$2017$ which is $2.4\%$ superior than other ViTs.
PDF Abstract


 ImageNet
ImageNet
 MS COCO
MS COCO
 ADE20K
ADE20K
