VLPrompt: Vision-Language Prompting for Panoptic Scene Graph Generation
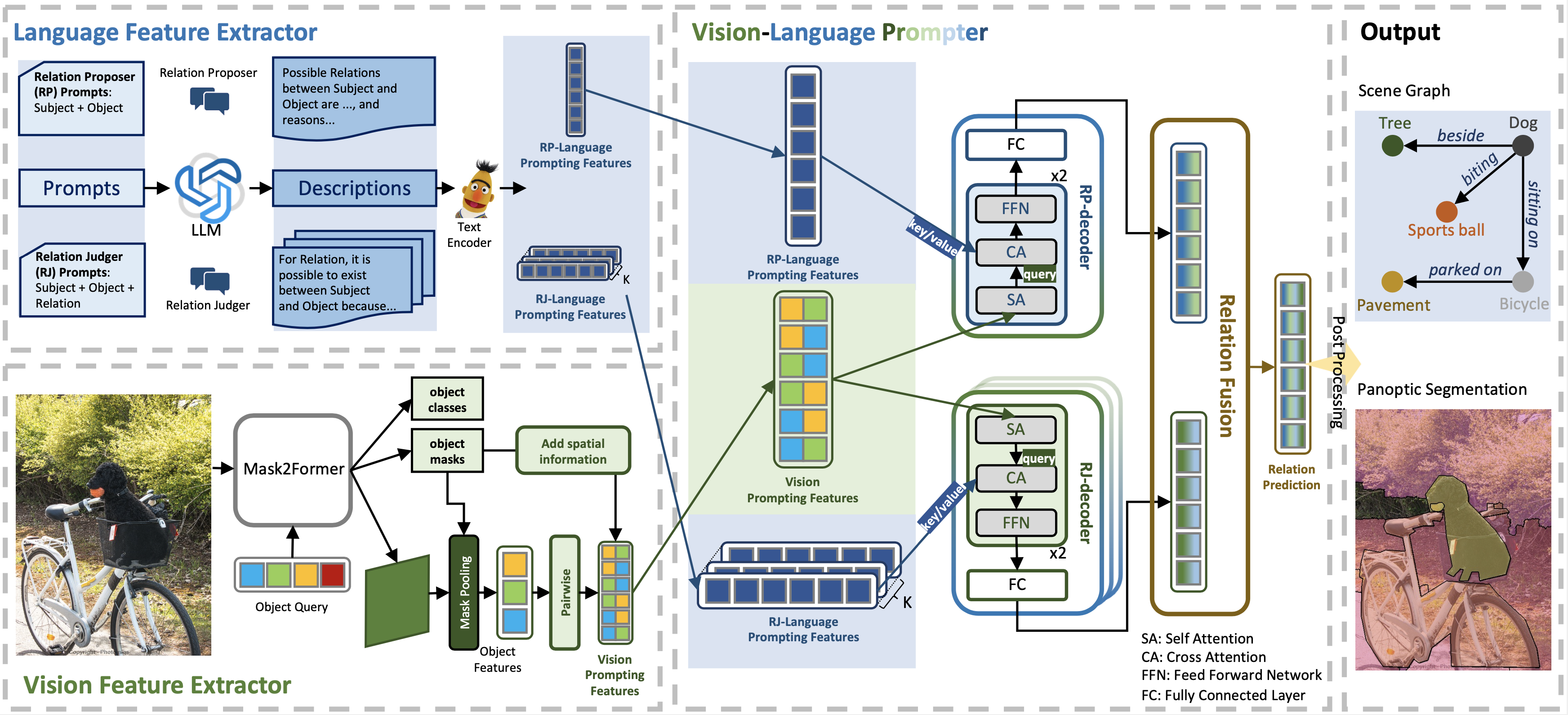
Panoptic Scene Graph Generation (PSG) aims at achieving a comprehensive image understanding by simultaneously segmenting objects and predicting relations among objects. However, the long-tail problem among relations leads to unsatisfactory results in real-world applications. Prior methods predominantly rely on vision information or utilize limited language information, such as object or relation names, thereby overlooking the utility of language information. Leveraging the recent progress in Large Language Models (LLMs), we propose to use language information to assist relation prediction, particularly for rare relations. To this end, we propose the Vision-Language Prompting (VLPrompt) model, which acquires vision information from images and language information from LLMs. Then, through a prompter network based on attention mechanism, it achieves precise relation prediction. Our extensive experiments show that VLPrompt significantly outperforms previous state-of-the-art methods on the PSG dataset, proving the effectiveness of incorporating language information and alleviating the long-tail problem of relations.
PDF Abstract

 PSG Dataset
PSG Dataset

