 Convolutions
Convolutions
Deformable Convolution
Introduced by Dai et al. in Deformable Convolutional NetworksDeformable convolutions add 2D offsets to the regular grid sampling locations in the standard convolution. It enables free form deformation of the sampling grid. The offsets are learned from the preceding feature maps, via additional convolutional layers. Thus, the deformation is conditioned on the input features in a local, dense, and adaptive manner.
Source: Deformable Convolutional Networks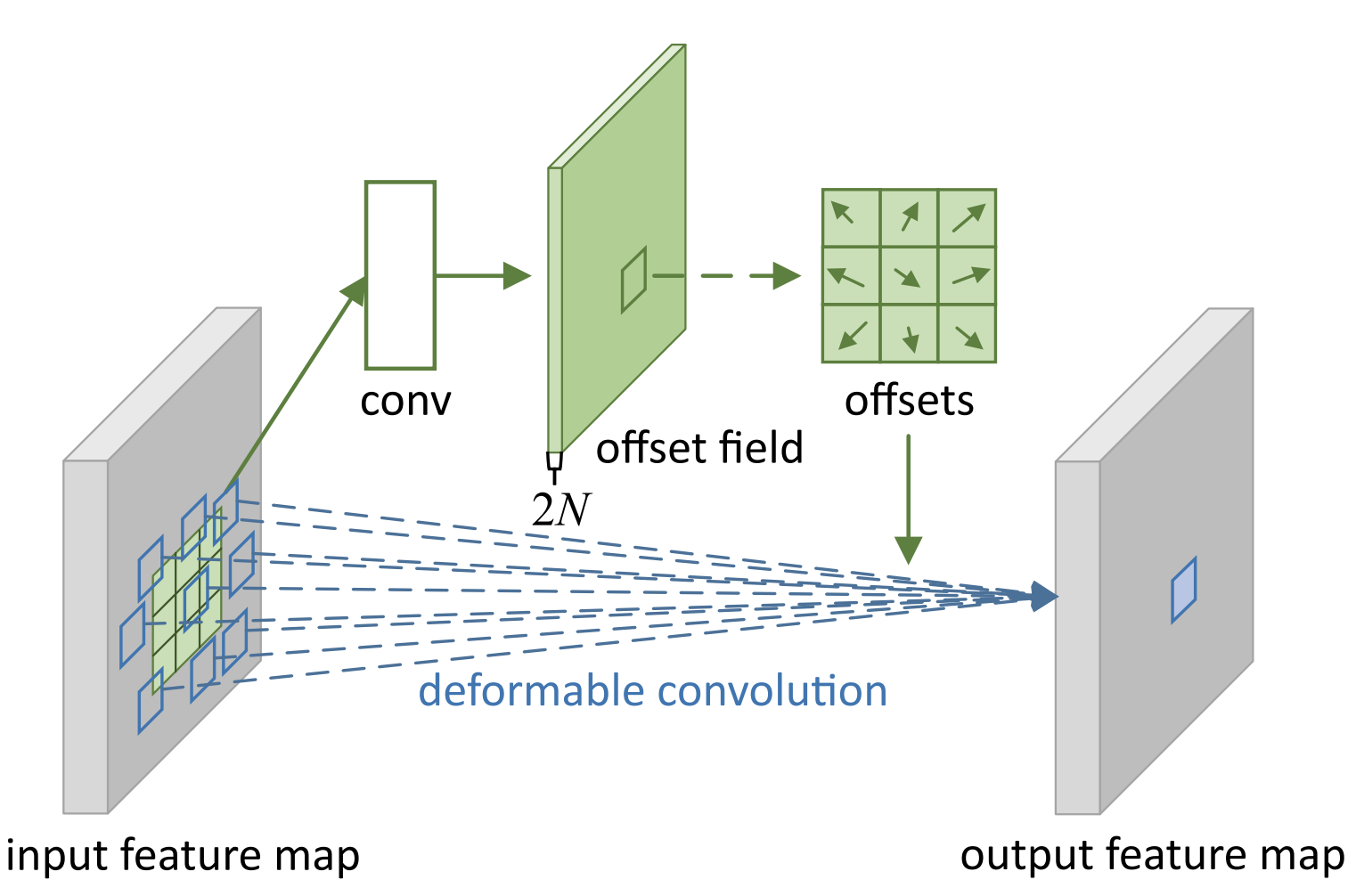
Papers
| Paper | Code | Results | Date | Stars |
|---|
Tasks
| Task | Papers | Share |
|---|---|---|
| Object Detection | 25 | 10.12% |
| Semantic Segmentation | 24 | 9.72% |
| Super-Resolution | 14 | 5.67% |
| Optical Flow Estimation | 10 | 4.05% |
| Instance Segmentation | 9 | 3.64% |
| Video Super-Resolution | 8 | 3.24% |
| Image Segmentation | 8 | 3.24% |
| Image Classification | 6 | 2.43% |
| Medical Image Segmentation | 6 | 2.43% |
Usage Over Time
Components
| Component | Type |
|
|---|---|---|
| 🤖 No Components Found | You can add them if they exist; e.g. Mask R-CNN uses RoIAlign |
