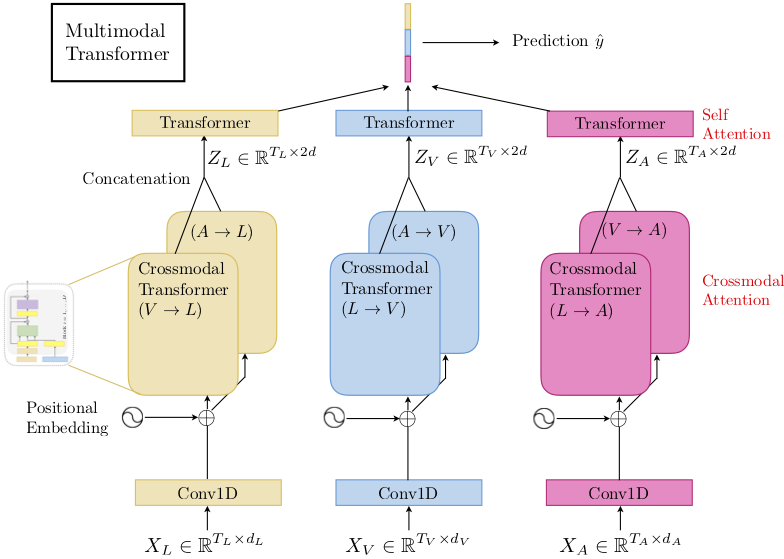
Multimodal Transformer for Unaligned Multimodal Language Sequences
Human language is often multimodal, which comprehends a mixture of natural language, facial gestures, and acoustic behaviors. However, two major challenges in modeling such multimodal human language time-series data exist: 1) inherent data non-alignment due to variable sampling rates for the sequences from each modality; and 2) long-range dependencies between elements across modalities. In this paper, we introduce the Multimodal Transformer (MulT) to generically address the above issues in an end-to-end manner without explicitly aligning the data. At the heart of our model is the directional pairwise crossmodal attention, which attends to interactions between multimodal sequences across distinct time steps and latently adapt streams from one modality to another. Comprehensive experiments on both aligned and non-aligned multimodal time-series show that our model outperforms state-of-the-art methods by a large margin. In addition, empirical analysis suggests that correlated crossmodal signals are able to be captured by the proposed crossmodal attention mechanism in MulT.
PDF Abstract ACL 2019 PDF ACL 2019 Abstract



 IEMOCAP
IEMOCAP
 CMU-MOSEI
CMU-MOSEI
 Multimodal Opinionlevel Sentiment Intensity
Multimodal Opinionlevel Sentiment Intensity

