3D Object Detection with a Self-supervised Lidar Scene Flow Backbone
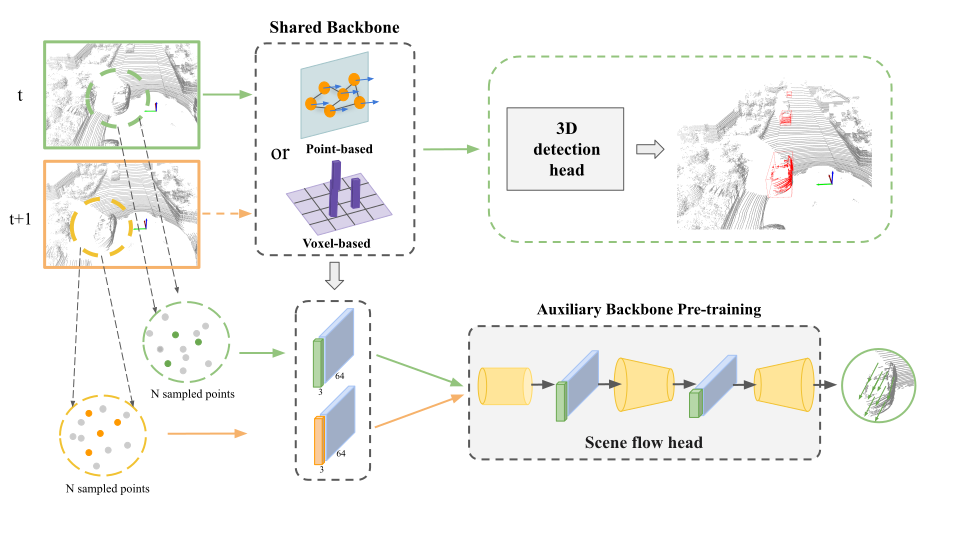
State-of-the-art lidar-based 3D object detection methods rely on supervised learning and large labeled datasets. However, annotating lidar data is resource-consuming, and depending only on supervised learning limits the applicability of trained models. Self-supervised training strategies can alleviate these issues by learning a general point cloud backbone model for downstream 3D vision tasks. Against this backdrop, we show the relationship between self-supervised multi-frame flow representations and single-frame 3D detection hypotheses. Our main contribution leverages learned flow and motion representations and combines a self-supervised backbone with a supervised 3D detection head. First, a self-supervised scene flow estimation model is trained with cycle consistency. Then, the point cloud encoder of this model is used as the backbone of a single-frame 3D object detection head model. This second 3D object detection model learns to utilize motion representations to distinguish dynamic objects exhibiting different movement patterns. Experiments on KITTI and nuScenes benchmarks show that the proposed self-supervised pre-training increases 3D detection performance significantly. https://github.com/emecercelik/ssl-3d-detection.git
PDF Abstract






 KITTI
KITTI
 nuScenes
nuScenes
