A Background-Agnostic Framework with Adversarial Training for Abnormal Event Detection in Video
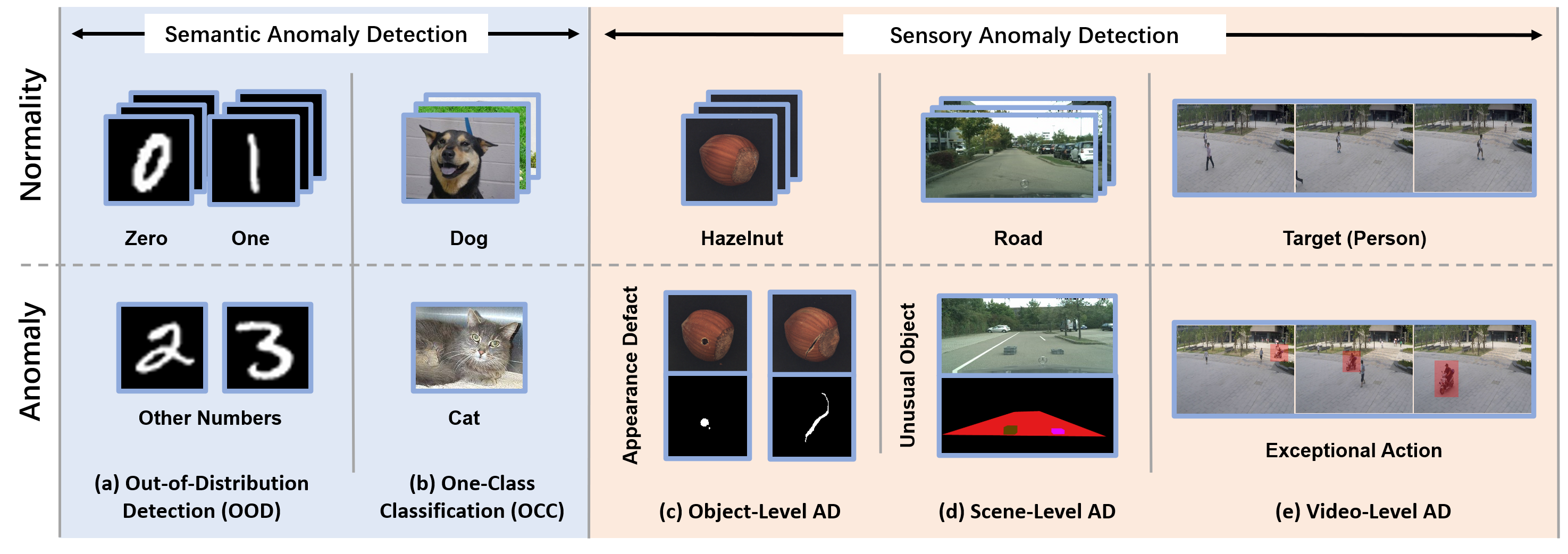
Abnormal event detection in video is a complex computer vision problem that has attracted significant attention in recent years. The complexity of the task arises from the commonly-adopted definition of an abnormal event, that is, a rarely occurring event that typically depends on the surrounding context. Following the standard formulation of abnormal event detection as outlier detection, we propose a background-agnostic framework that learns from training videos containing only normal events. Our framework is composed of an object detector, a set of appearance and motion auto-encoders, and a set of classifiers. Since our framework only looks at object detections, it can be applied to different scenes, provided that normal events are defined identically across scenes and that the single main factor of variation is the background. To overcome the lack of abnormal data during training, we propose an adversarial learning strategy for the auto-encoders. We create a scene-agnostic set of out-of-domain pseudo-abnormal examples, which are correctly reconstructed by the auto-encoders before applying gradient ascent on the pseudo-abnormal examples. We further utilize the pseudo-abnormal examples to serve as abnormal examples when training appearance-based and motion-based binary classifiers to discriminate between normal and abnormal latent features and reconstructions. We compare our framework with the state-of-the-art methods on four benchmark data sets, using various evaluation metrics. Compared to existing methods, the empirical results indicate that our approach achieves favorable performance on all data sets. In addition, we provide region-based and track-based annotations for two large-scale abnormal event detection data sets from the literature, namely ShanghaiTech and Subway.
PDF Abstract


 MS COCO
MS COCO
 ssd
ssd
 ShanghaiTech
ShanghaiTech
 ShanghaiTech Campus
ShanghaiTech Campus
 UCSD Ped2
UCSD Ped2
 UBnormal
UBnormal
 Street Scene
Street Scene

