ActionFormer: Localizing Moments of Actions with Transformers
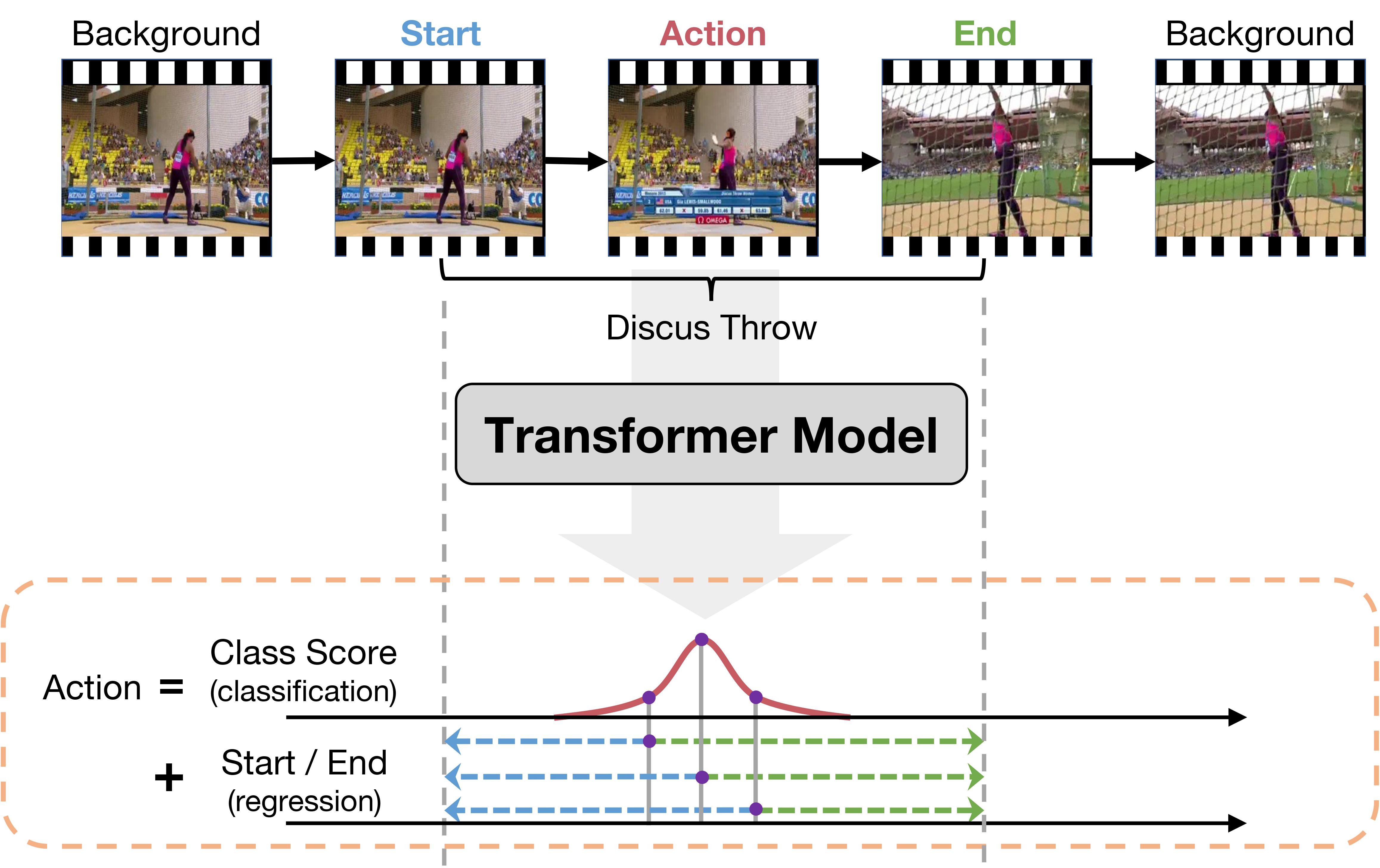
Self-attention based Transformer models have demonstrated impressive results for image classification and object detection, and more recently for video understanding. Inspired by this success, we investigate the application of Transformer networks for temporal action localization in videos. To this end, we present ActionFormer -- a simple yet powerful model to identify actions in time and recognize their categories in a single shot, without using action proposals or relying on pre-defined anchor windows. ActionFormer combines a multiscale feature representation with local self-attention, and uses a light-weighted decoder to classify every moment in time and estimate the corresponding action boundaries. We show that this orchestrated design results in major improvements upon prior works. Without bells and whistles, ActionFormer achieves 71.0% mAP at tIoU=0.5 on THUMOS14, outperforming the best prior model by 14.1 absolute percentage points. Further, ActionFormer demonstrates strong results on ActivityNet 1.3 (36.6% average mAP) and EPIC-Kitchens 100 (+13.5% average mAP over prior works). Our code is available at http://github.com/happyharrycn/actionformer_release.
PDF Abstract



 ActivityNet
ActivityNet
 THUMOS14
THUMOS14
 EPIC-KITCHENS-100
EPIC-KITCHENS-100
 UnAV-100
UnAV-100

