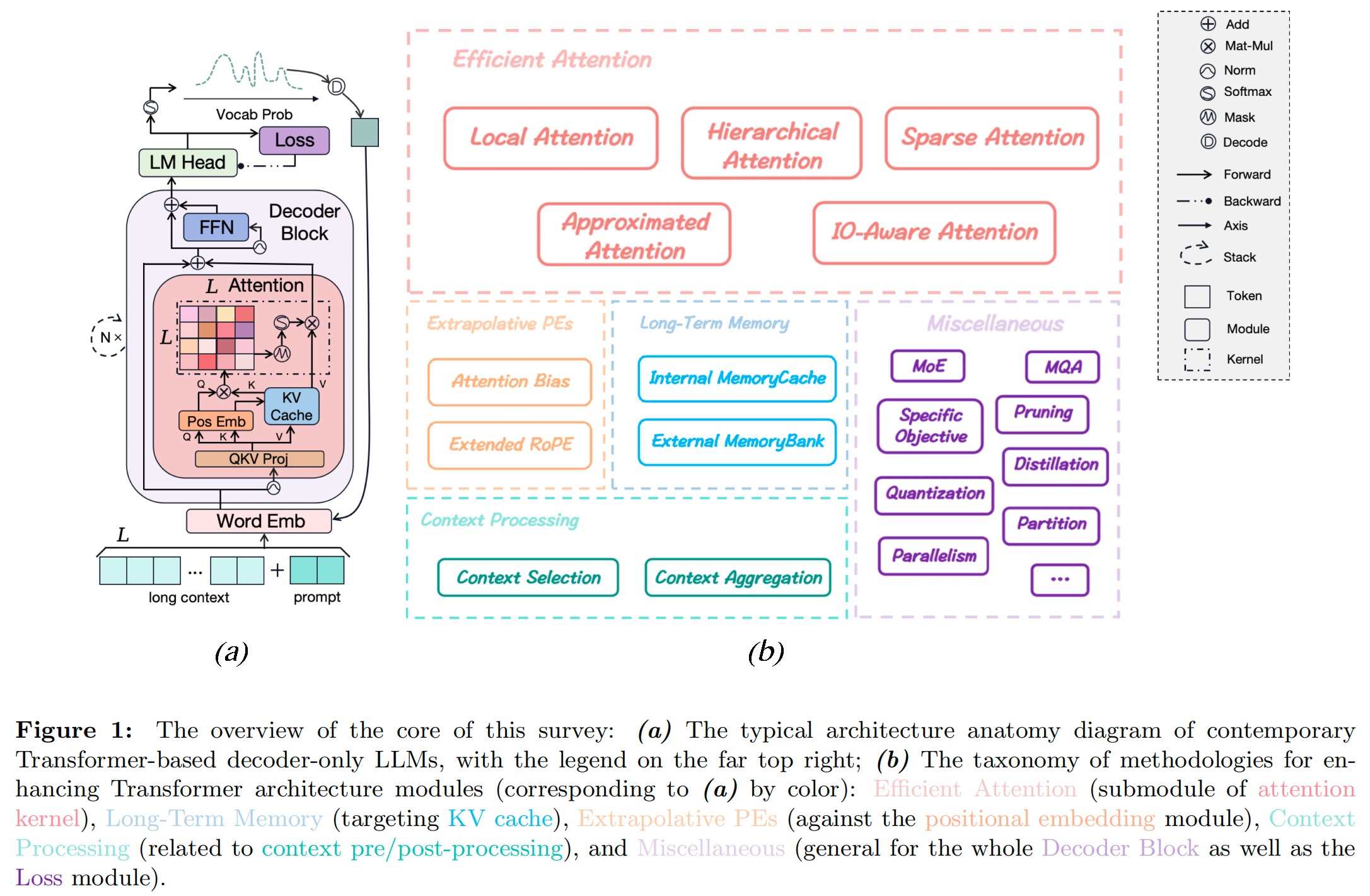
Advancing Transformer Architecture in Long-Context Large Language Models: A Comprehensive Survey
Transformer-based Large Language Models (LLMs) have been applied in diverse areas such as knowledge bases, human interfaces, and dynamic agents, and marking a stride towards achieving Artificial General Intelligence (AGI). However, current LLMs are predominantly pretrained on short text snippets, which compromises their effectiveness in processing the long-context prompts that are frequently encountered in practical scenarios. This article offers a comprehensive survey of the recent advancement in Transformer-based LLM architectures aimed at enhancing the long-context capabilities of LLMs throughout the entire model lifecycle, from pre-training through to inference. We first delineate and analyze the problems of handling long-context input and output with the current Transformer-based models. We then provide a taxonomy and the landscape of upgrades on Transformer architecture to solve these problems. Afterwards, we provide an investigation on wildly used evaluation necessities tailored for long-context LLMs, including datasets, metrics, and baseline models, as well as optimization toolkits such as libraries, frameworks, and compilers to boost the efficacy of LLMs across different stages in runtime. Finally, we discuss the challenges and potential avenues for future research. A curated repository of relevant literature, continuously updated, is available at https://github.com/Strivin0311/long-llms-learning.
PDF Abstract

