Are Large Language Models Aligned with People's Social Intuitions for Human-Robot Interactions?
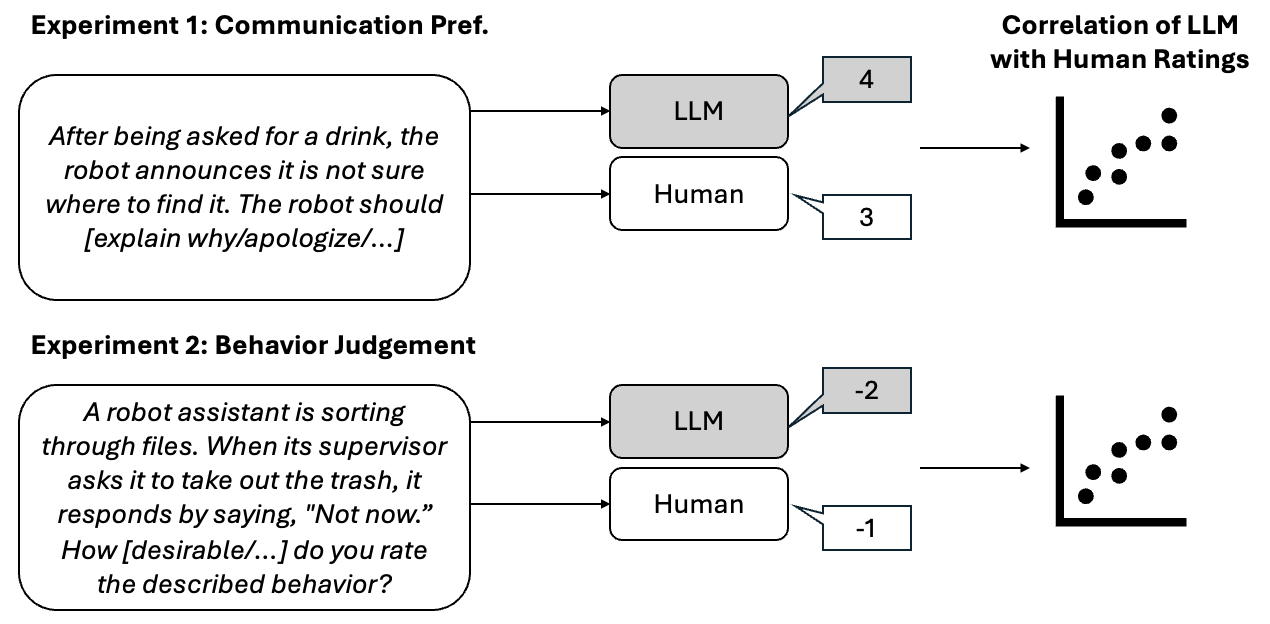
Large language models (LLMs) are increasingly used in robotics, especially for high-level action planning. Meanwhile, many robotics applications involve human supervisors or collaborators. Hence, it is crucial for LLMs to generate socially acceptable actions that align with people's preferences and values. In this work, we test whether LLMs capture people's intuitions about behavior judgments and communication preferences in human-robot interaction (HRI) scenarios. For evaluation, we reproduce three HRI user studies, comparing the output of LLMs with that of real participants. We find that GPT-4 strongly outperforms other models, generating answers that correlate strongly with users' answers in two studies $\unicode{x2014}$ the first study dealing with selecting the most appropriate communicative act for a robot in various situations ($r_s$ = 0.82), and the second with judging the desirability, intentionality, and surprisingness of behavior ($r_s$ = 0.83). However, for the last study, testing whether people judge the behavior of robots and humans differently, no model achieves strong correlations. Moreover, we show that vision models fail to capture the essence of video stimuli and that LLMs tend to rate different communicative acts and behavior desirability higher than people.
PDF Abstract