CMKD: CNN/Transformer-Based Cross-Model Knowledge Distillation for Audio Classification
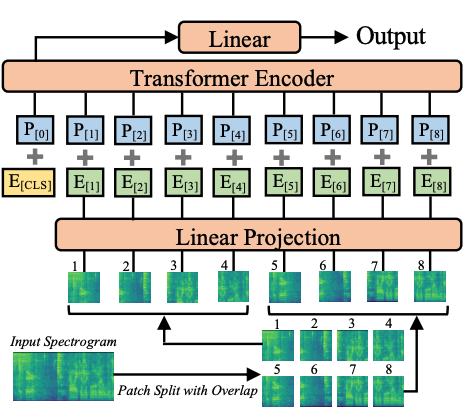
Audio classification is an active research area with a wide range of applications. Over the past decade, convolutional neural networks (CNNs) have been the de-facto standard building block for end-to-end audio classification models. Recently, neural networks based solely on self-attention mechanisms such as the Audio Spectrogram Transformer (AST) have been shown to outperform CNNs. In this paper, we find an intriguing interaction between the two very different models - CNN and AST models are good teachers for each other. When we use either of them as the teacher and train the other model as the student via knowledge distillation (KD), the performance of the student model noticeably improves, and in many cases, is better than the teacher model. In our experiments with this CNN/Transformer Cross-Model Knowledge Distillation (CMKD) method we achieve new state-of-the-art performance on FSD50K, AudioSet, and ESC-50.
PDF Abstract Colab
Colab


 AudioSet
AudioSet
 ESC-50
ESC-50
 FSD50K
FSD50K
