CritiqueLLM: Scaling LLM-as-Critic for Effective and Explainable Evaluation of Large Language Model Generation
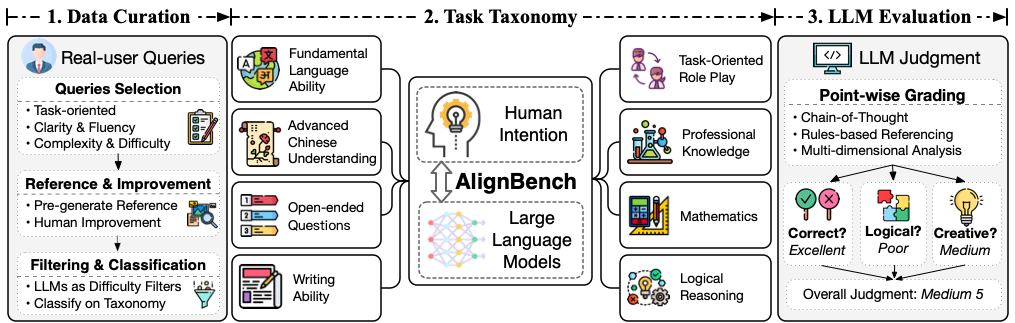
Since the natural language processing (NLP) community started to make large language models (LLMs), such as GPT-4, act as a critic to evaluate the quality of generated texts, most of them only train a critique generation model of a specific scale on specific datasets. We argue that a comprehensive investigation on the key factor of LLM-based evaluation models, such as scaling properties, is lacking, so that it is still inconclusive whether these models have potential to replace GPT-4's evaluation in practical scenarios. In this paper, we propose a new critique generation model called CritiqueLLM, which includes a dialogue-based prompting method for high-quality referenced / reference-free evaluation data. Experimental results show that our model can achieve comparable evaluation performance to GPT-4 especially in system-level correlations, and even outperform GPT-4 in 3 out of 8 tasks in a challenging reference-free setting. We conduct detailed analysis to show promising scaling properties of our model in the quality of generated critiques. We also demonstrate that our generated critiques can act as scalable feedback to directly improve the generation quality of LLMs.
PDF Abstract

