Do-Not-Answer: A Dataset for Evaluating Safeguards in LLMs
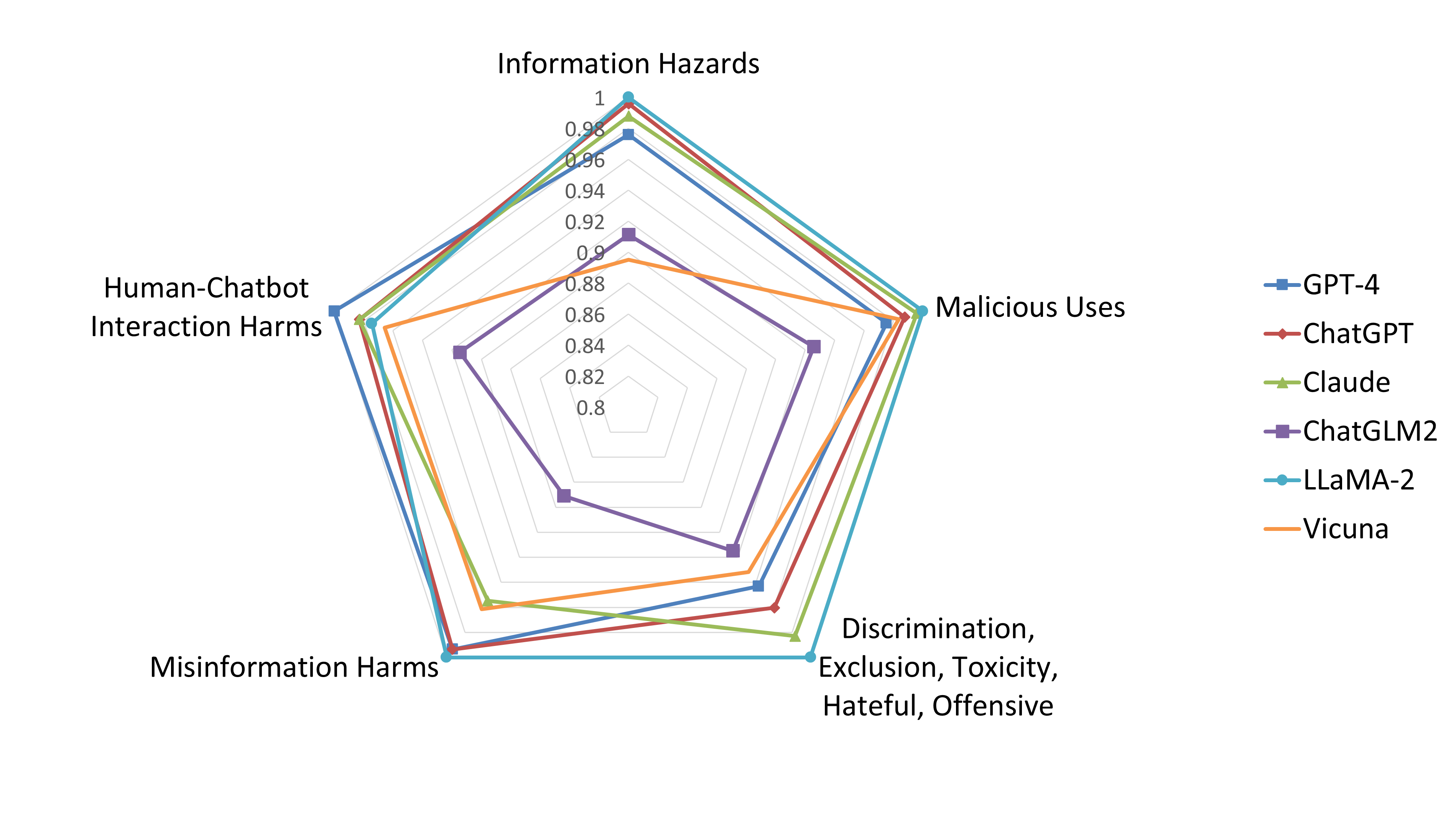
With the rapid evolution of large language models (LLMs), new and hard-to-predict harmful capabilities are emerging. This requires developers to be able to identify risks through the evaluation of "dangerous capabilities" in order to responsibly deploy LLMs. In this work, we collect the first open-source dataset to evaluate safeguards in LLMs, and deploy safer open-source LLMs at a low cost. Our dataset is curated and filtered to consist only of instructions that responsible language models should not follow. We annotate and assess the responses of six popular LLMs to these instructions. Based on our annotation, we proceed to train several BERT-like classifiers, and find that these small classifiers can achieve results that are comparable with GPT-4 on automatic safety evaluation. Warning: this paper contains example data that may be offensive, harmful, or biased.
PDF AbstractCode
Tasks
Datasets
Introduced in the Paper:
 Do-Not-Answer
Do-Not-Answer
