DocSegTr: An Instance-Level End-to-End Document Image Segmentation Transformer
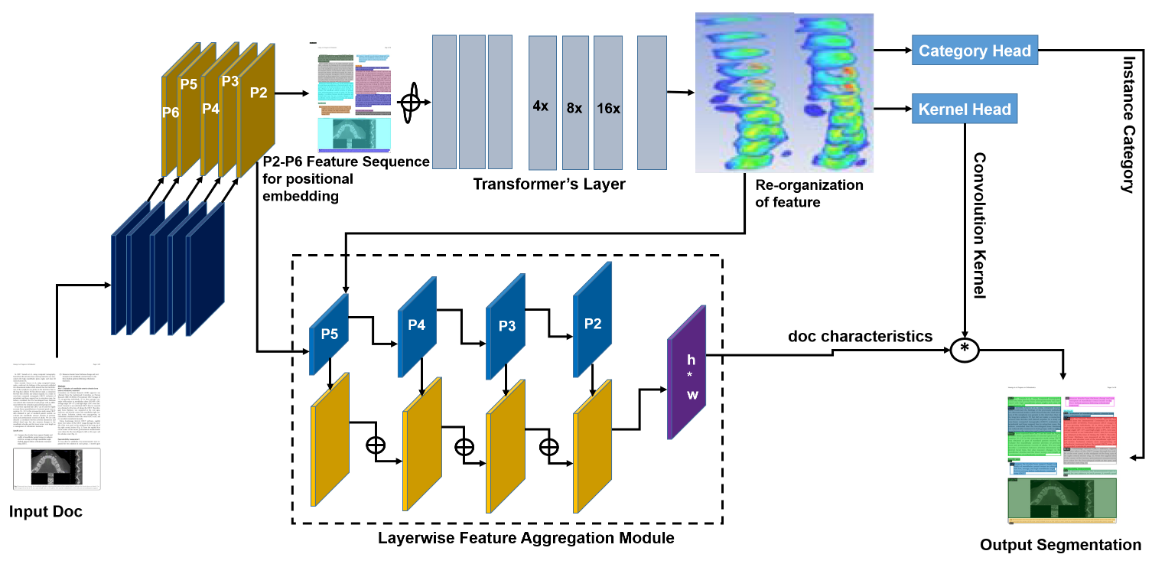
Understanding documents with rich layouts is an essential step towards information extraction. Business intelligence processes often require the extraction of useful semantic content from documents at a large scale for subsequent decision-making tasks. In this context, instance-level segmentation of different document objects (title, sections, figures etc.) has emerged as an interesting problem for the document analysis and understanding community. To advance the research in this direction, we present a transformer-based model called \emph{DocSegTr} for end-to-end instance segmentation of complex layouts in document images. The method adapts a twin attention module, for semantic reasoning, which helps to become highly computationally efficient compared with the state-of-the-art. To the best of our knowledge, this is the first work on transformer-based document segmentation. Extensive experimentation on competitive benchmarks like PubLayNet, PRIMA, Historical Japanese (HJ) and TableBank demonstrate that our model achieved comparable or better segmentation performance than the existing state-of-the-art approaches with the average precision of 89.4, 40.3, 83.4 and 93.3. This simple and flexible framework could serve as a promising baseline for instance-level recognition tasks in document images.
PDF Abstract




