Efficient Multimodal Transformer with Dual-Level Feature Restoration for Robust Multimodal Sentiment Analysis
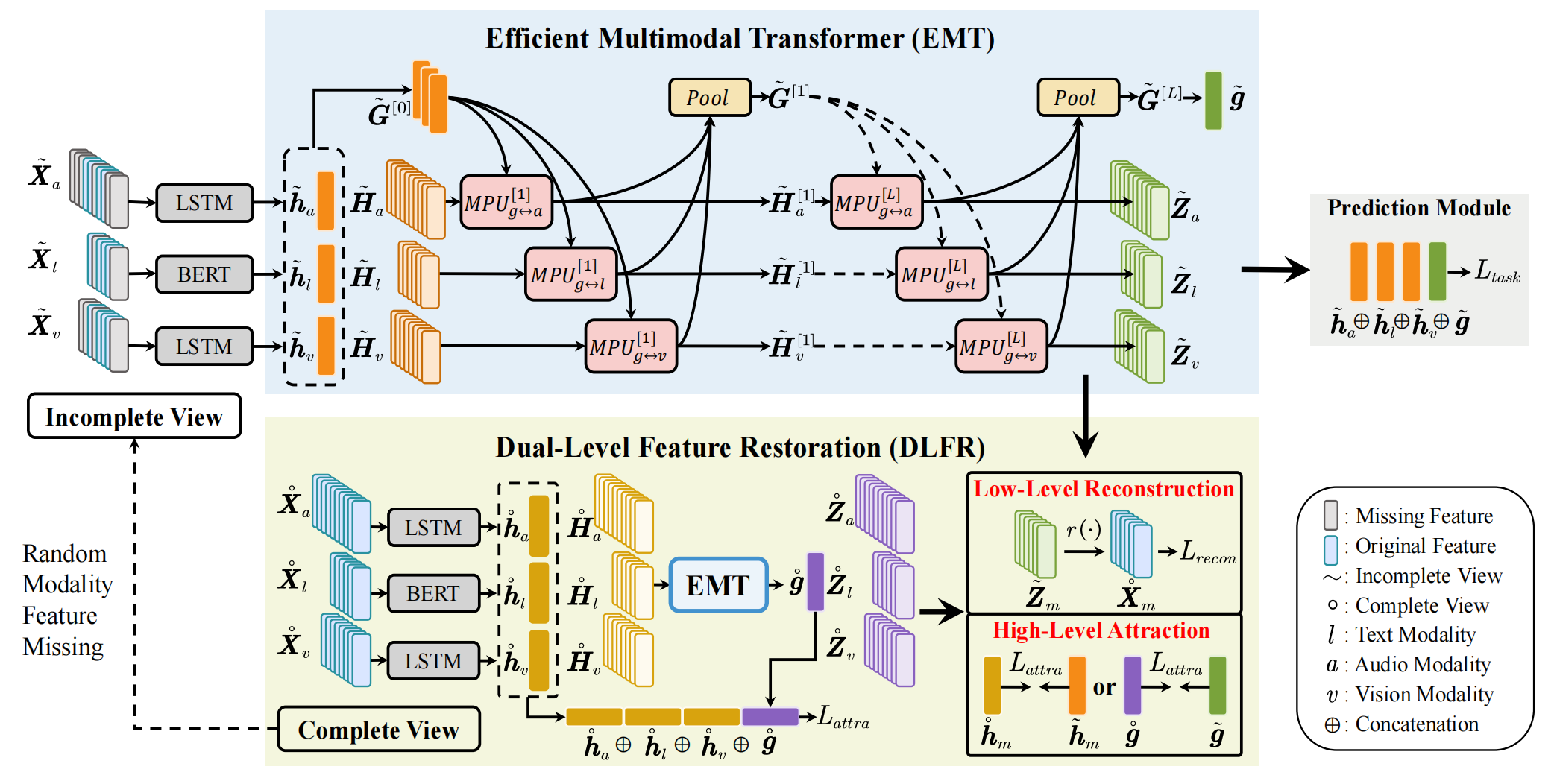
With the proliferation of user-generated online videos, Multimodal Sentiment Analysis (MSA) has attracted increasing attention recently. Despite significant progress, there are still two major challenges on the way towards robust MSA: 1) inefficiency when modeling cross-modal interactions in unaligned multimodal data; and 2) vulnerability to random modality feature missing which typically occurs in realistic settings. In this paper, we propose a generic and unified framework to address them, named Efficient Multimodal Transformer with Dual-Level Feature Restoration (EMT-DLFR). Concretely, EMT employs utterance-level representations from each modality as the global multimodal context to interact with local unimodal features and mutually promote each other. It not only avoids the quadratic scaling cost of previous local-local cross-modal interaction methods but also leads to better performance. To improve model robustness in the incomplete modality setting, on the one hand, DLFR performs low-level feature reconstruction to implicitly encourage the model to learn semantic information from incomplete data. On the other hand, it innovatively regards complete and incomplete data as two different views of one sample and utilizes siamese representation learning to explicitly attract their high-level representations. Comprehensive experiments on three popular datasets demonstrate that our method achieves superior performance in both complete and incomplete modality settings.
PDF Abstract



 CMU-MOSEI
CMU-MOSEI
 CH-SIMS
CH-SIMS
