From Words to Numbers: Your Large Language Model Is Secretly A Capable Regressor When Given In-Context Examples
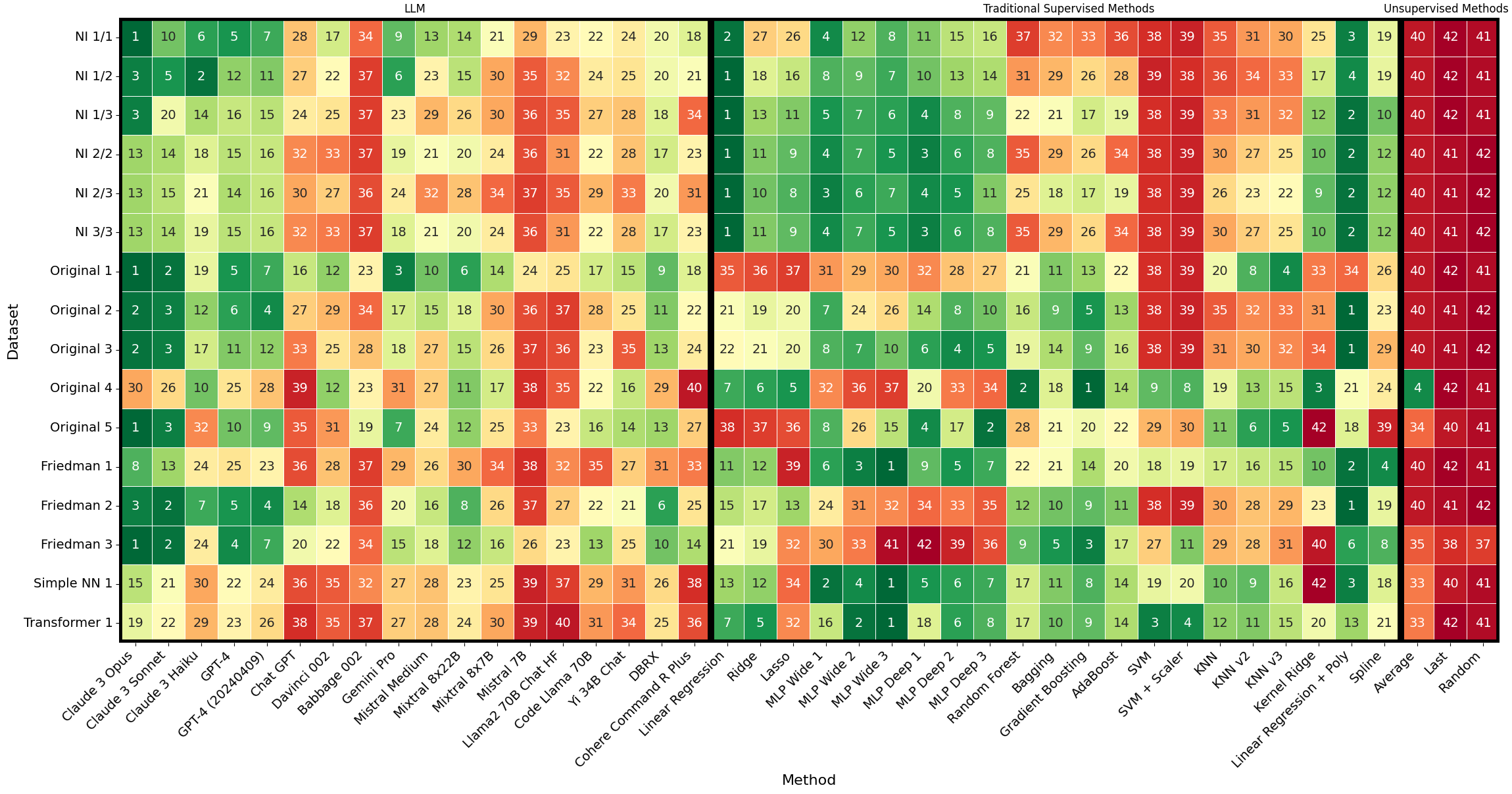
We analyze how well pre-trained large language models (e.g., Llama2, GPT-4, Claude 3, etc) can do linear and non-linear regression when given in-context examples, without any additional training or gradient updates. Our findings reveal that several large language models (e.g., GPT-4, Claude 3) are able to perform regression tasks with a performance rivaling (or even outperforming) that of traditional supervised methods such as Random Forest, Bagging, or Gradient Boosting. For example, on the challenging Friedman #2 regression dataset, Claude 3 outperforms many supervised methods such as AdaBoost, SVM, Random Forest, KNN, or Gradient Boosting. We then investigate how well the performance of large language models scales with the number of in-context exemplars. We borrow from the notion of regret from online learning and empirically show that LLMs are capable of obtaining a sub-linear regret.
PDF Abstract Colab
Colab
 Spaces
Spaces


