Imitation Learning with Human Eye Gaze via Multi-Objective Prediction
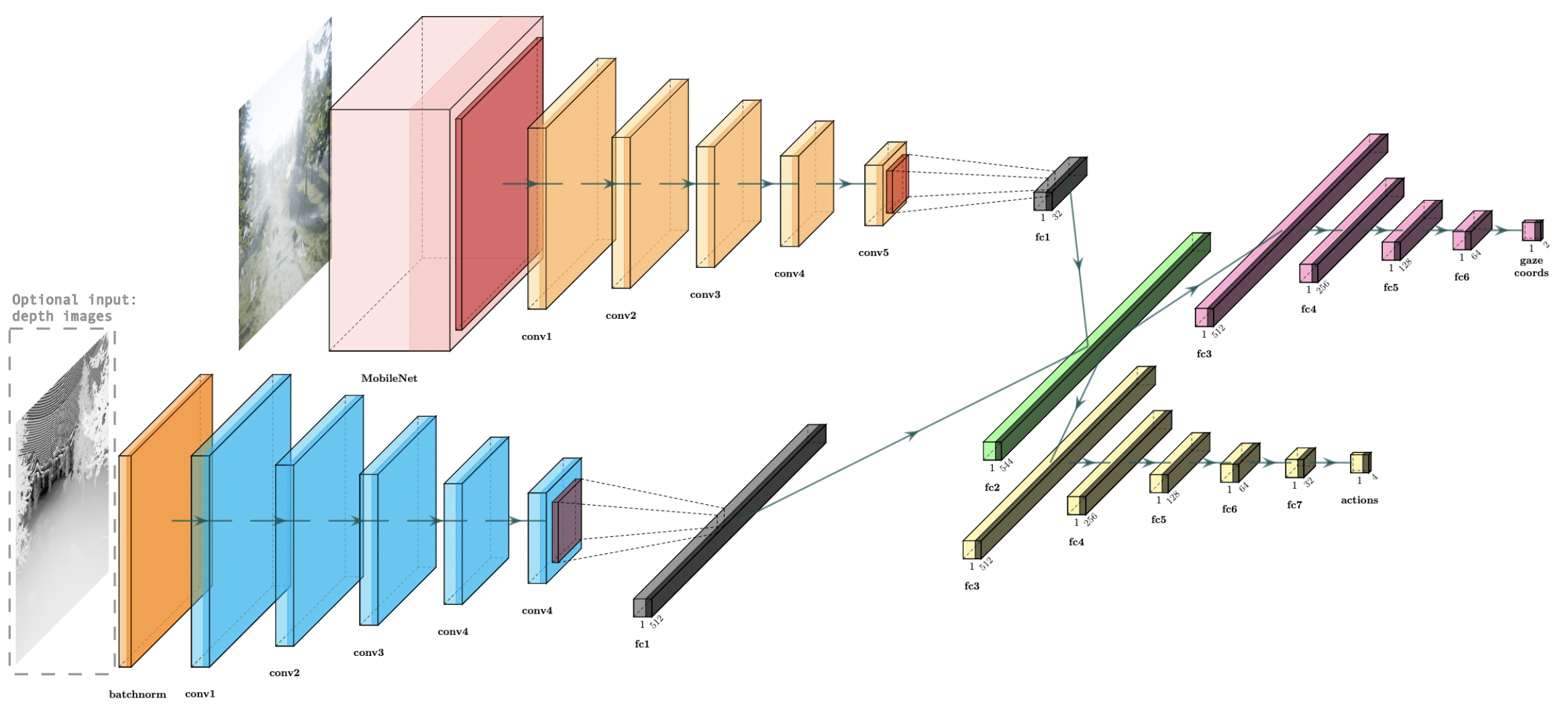
Approaches for teaching learning agents via human demonstrations have been widely studied and successfully applied to multiple domains. However, the majority of imitation learning work utilizes only behavioral information from the demonstrator, i.e. which actions were taken, and ignores other useful information. In particular, eye gaze information can give valuable insight towards where the demonstrator is allocating visual attention, and holds the potential to improve agent performance and generalization. In this work, we propose Gaze Regularized Imitation Learning (GRIL), a novel context-aware, imitation learning architecture that learns concurrently from both human demonstrations and eye gaze to solve tasks where visual attention provides important context. We apply GRIL to a visual navigation task, in which an unmanned quadrotor is trained to search for and navigate to a target vehicle in a photorealistic simulated environment. We show that GRIL outperforms several state-of-the-art gaze-based imitation learning algorithms, simultaneously learns to predict human visual attention, and generalizes to scenarios not present in the training data. Supplemental videos and code can be found at https://sites.google.com/view/gaze-regularized-il/.
PDF Abstract


 Atari-HEAD
Atari-HEAD
