HuatuoGPT, towards Taming Language Model to Be a Doctor
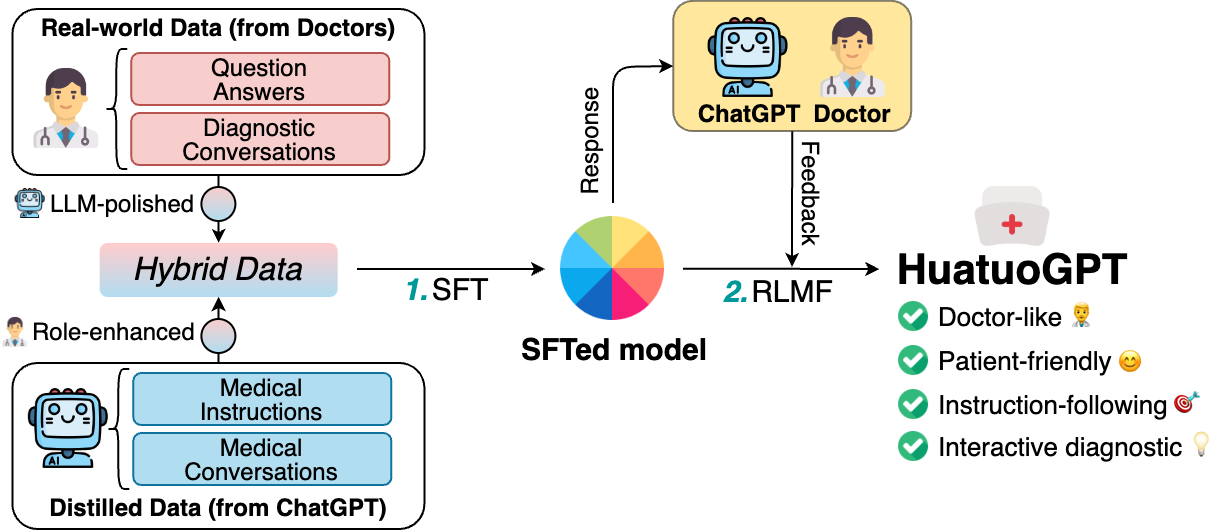
In this paper, we present HuatuoGPT, a large language model (LLM) for medical consultation. The core recipe of HuatuoGPT is to leverage both \textit{distilled data from ChatGPT} and \textit{real-world data from doctors} in the supervised fine-tuned stage. The responses of ChatGPT are usually detailed, well-presented and informative while it cannot perform like a doctor in many aspects, e.g. for integrative diagnosis. We argue that real-world data from doctors would be complementary to distilled data in the sense the former could tame a distilled language model to perform like doctors. To better leverage the strengths of both data, we train a reward model to align the language model with the merits that both data bring, following an RLAIF (reinforced learning from AI feedback) fashion. To evaluate and benchmark the models, we propose a comprehensive evaluation scheme (including automatic and manual metrics). Experimental results demonstrate that HuatuoGPT achieves state-of-the-art results in performing medical consultation among open-source LLMs in GPT-4 evaluation, human evaluation, and medical benchmark datasets. It is worth noting that by using additional real-world data and RLAIF, the distilled language model (i.e., HuatuoGPT) outperforms its teacher model ChatGPT in most cases. Our code, data, and models are publicly available at \url{https://github.com/FreedomIntelligence/HuatuoGPT}. The online demo is available at \url{https://www.HuatuoGPT.cn/}.
PDF Abstract


 The Pile
The Pile
