Inducing Systematicity in Transformers by Attending to Structurally Quantized Embeddings
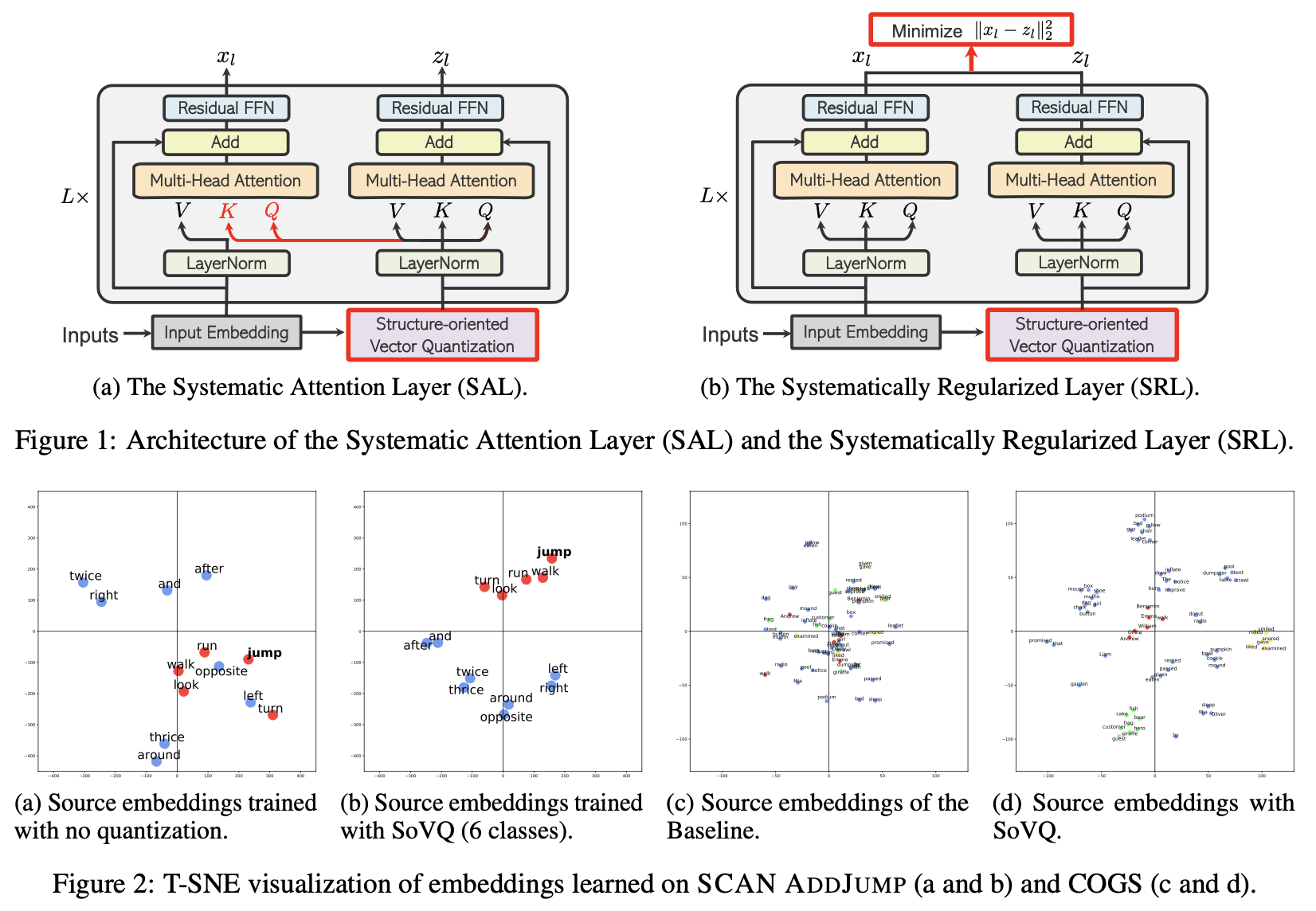
Transformers generalize to novel compositions of structures and entities after being trained on a complex dataset, but easily overfit on datasets of insufficient complexity. We observe that when the training set is sufficiently complex, the model encodes sentences that have a common syntactic structure using a systematic attention pattern. Inspired by this observation, we propose SQ-Transformer (Structurally Quantized) that explicitly encourages systematicity in the embeddings and attention layers, even with a training set of low complexity. At the embedding level, we introduce Structure-oriented Vector Quantization (SoVQ) to cluster word embeddings into several classes of structurally equivalent entities. At the attention level, we devise the Systematic Attention Layer (SAL) and an alternative, Systematically Regularized Layer (SRL) that operate on the quantized word embeddings so that sentences of the same structure are encoded with invariant or similar attention patterns. Empirically, we show that SQ-Transformer achieves stronger compositional generalization than the vanilla Transformer on multiple low-complexity semantic parsing and machine translation datasets. In our analysis, we show that SoVQ indeed learns a syntactically clustered embedding space and SAL/SRL induces generalizable attention patterns, which lead to improved systematicity.
PDF Abstract



 WMT 2014
WMT 2014
 SCAN
SCAN
