Jigsaw-ViT: Learning Jigsaw Puzzles in Vision Transformer
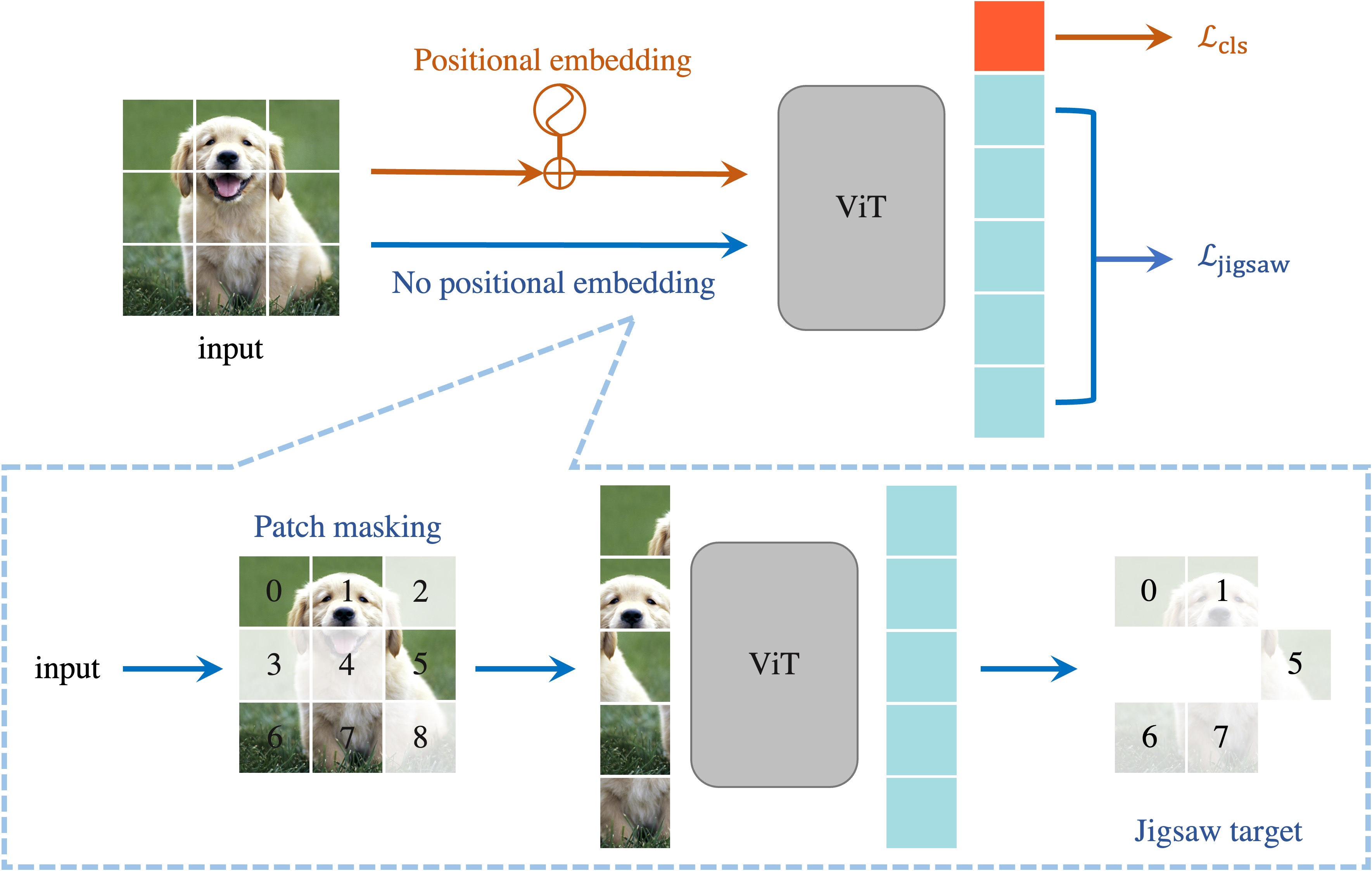
The success of Vision Transformer (ViT) in various computer vision tasks has promoted the ever-increasing prevalence of this convolution-free network. The fact that ViT works on image patches makes it potentially relevant to the problem of jigsaw puzzle solving, which is a classical self-supervised task aiming at reordering shuffled sequential image patches back to their natural form. Despite its simplicity, solving jigsaw puzzle has been demonstrated to be helpful for diverse tasks using Convolutional Neural Networks (CNNs), such as self-supervised feature representation learning, domain generalization, and fine-grained classification. In this paper, we explore solving jigsaw puzzle as a self-supervised auxiliary loss in ViT for image classification, named Jigsaw-ViT. We show two modifications that can make Jigsaw-ViT superior to standard ViT: discarding positional embeddings and masking patches randomly. Yet simple, we find that Jigsaw-ViT is able to improve both in generalization and robustness over the standard ViT, which is usually rather a trade-off. Experimentally, we show that adding the jigsaw puzzle branch provides better generalization than ViT on large-scale image classification on ImageNet. Moreover, the auxiliary task also improves robustness to noisy labels on Animal-10N, Food-101N, and Clothing1M as well as adversarial examples. Our implementation is available at https://yingyichen-cyy.github.io/Jigsaw-ViT/.
PDF Abstract




 ImageNet
ImageNet
 Clothing1M
Clothing1M
 ANIMAL
ANIMAL

