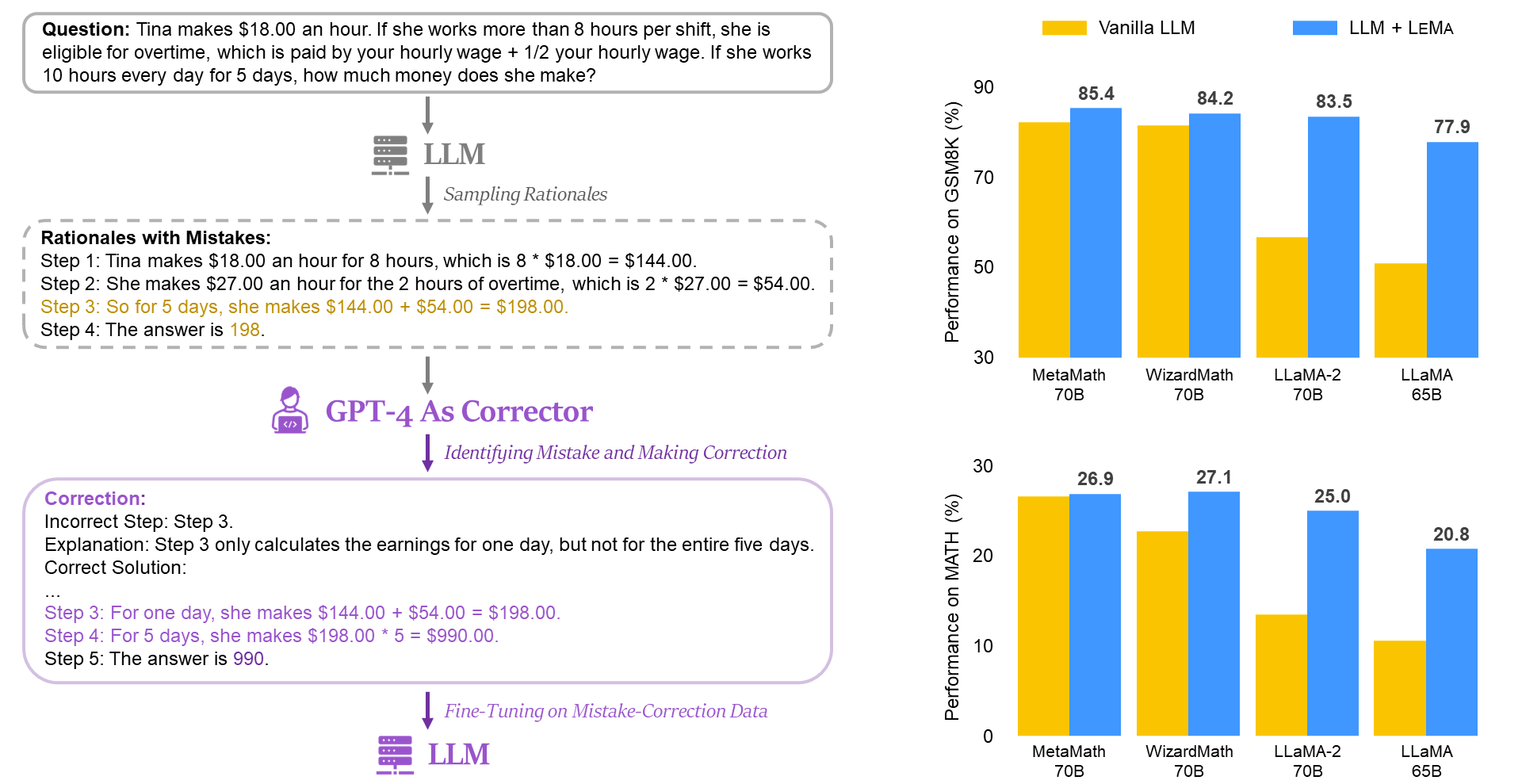
Learning From Mistakes Makes LLM Better Reasoner
Large language models (LLMs) recently exhibited remarkable reasoning capabilities on solving math problems. To further improve their reasoning capabilities, this work explores whether LLMs can LEarn from MistAkes (LEMA), akin to the human learning process. Consider a human student who failed to solve a math problem, he will learn from what mistake he has made and how to correct it. Mimicking this error-driven learning process, LEMA incorporates mistake-correction data pairs during fine-tuning LLMs. Specifically, we first collect inaccurate reasoning paths from various LLMs, and then employ GPT-4 as a ''corrector'' to identify the mistake step, explain the reason for the mistake, correct the mistake and generate the final answer. In addition, we apply a correction-centric evolution strategy that effectively expands the question set for generating correction data. Experiments across various LLMs and reasoning tasks show that LEMA effectively improves CoT-alone fine-tuning. Our further ablations shed light on the non-homogeneous effectiveness between CoT data and correction data. These results suggest a significant potential for LLMs to improve through learning from their mistakes. Our code, models and prompts are publicly available at https://github.com/microsoft/LEMA.
PDF Abstract

 GSM8K
GSM8K
 MATH
MATH
 SVAMP
SVAMP
