Learning How To Robustly Estimate Camera Pose in Endoscopic Videos
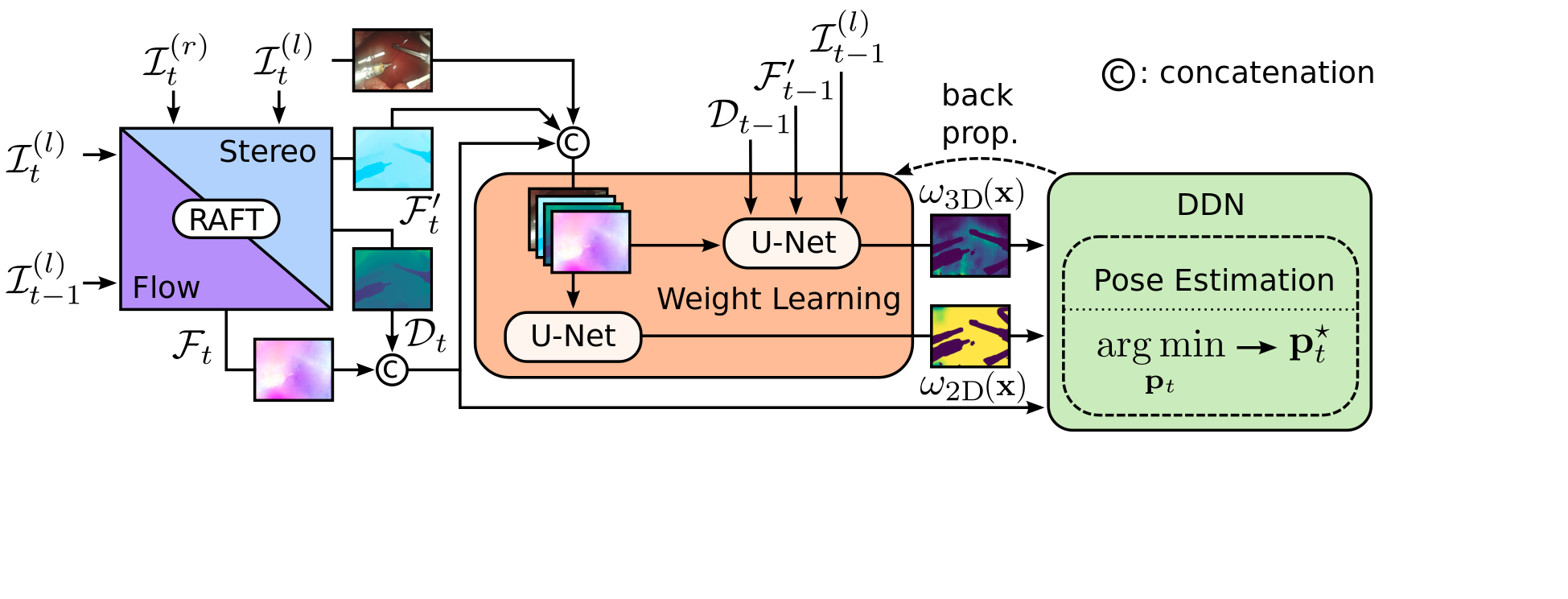
Purpose: Surgical scene understanding plays a critical role in the technology stack of tomorrow's intervention-assisting systems in endoscopic surgeries. For this, tracking the endoscope pose is a key component, but remains challenging due to illumination conditions, deforming tissues and the breathing motion of organs. Method: We propose a solution for stereo endoscopes that estimates depth and optical flow to minimize two geometric losses for camera pose estimation. Most importantly, we introduce two learned adaptive per-pixel weight mappings that balance contributions according to the input image content. To do so, we train a Deep Declarative Network to take advantage of the expressiveness of deep-learning and the robustness of a novel geometric-based optimization approach. We validate our approach on the publicly available SCARED dataset and introduce a new in-vivo dataset, StereoMIS, which includes a wider spectrum of typically observed surgical settings. Results: Our method outperforms state-of-the-art methods on average and more importantly, in difficult scenarios where tissue deformations and breathing motion are visible. We observed that our proposed weight mappings attenuate the contribution of pixels on ambiguous regions of the images, such as deforming tissues. Conclusion: We demonstrate the effectiveness of our solution to robustly estimate the camera pose in challenging endoscopic surgical scenes. Our contributions can be used to improve related tasks like simultaneous localization and mapping (SLAM) or 3D reconstruction, therefore advancing surgical scene understanding in minimally-invasive surgery.
PDF Abstract





