Magic Tokens: Select Diverse Tokens for Multi-modal Object Re-Identification
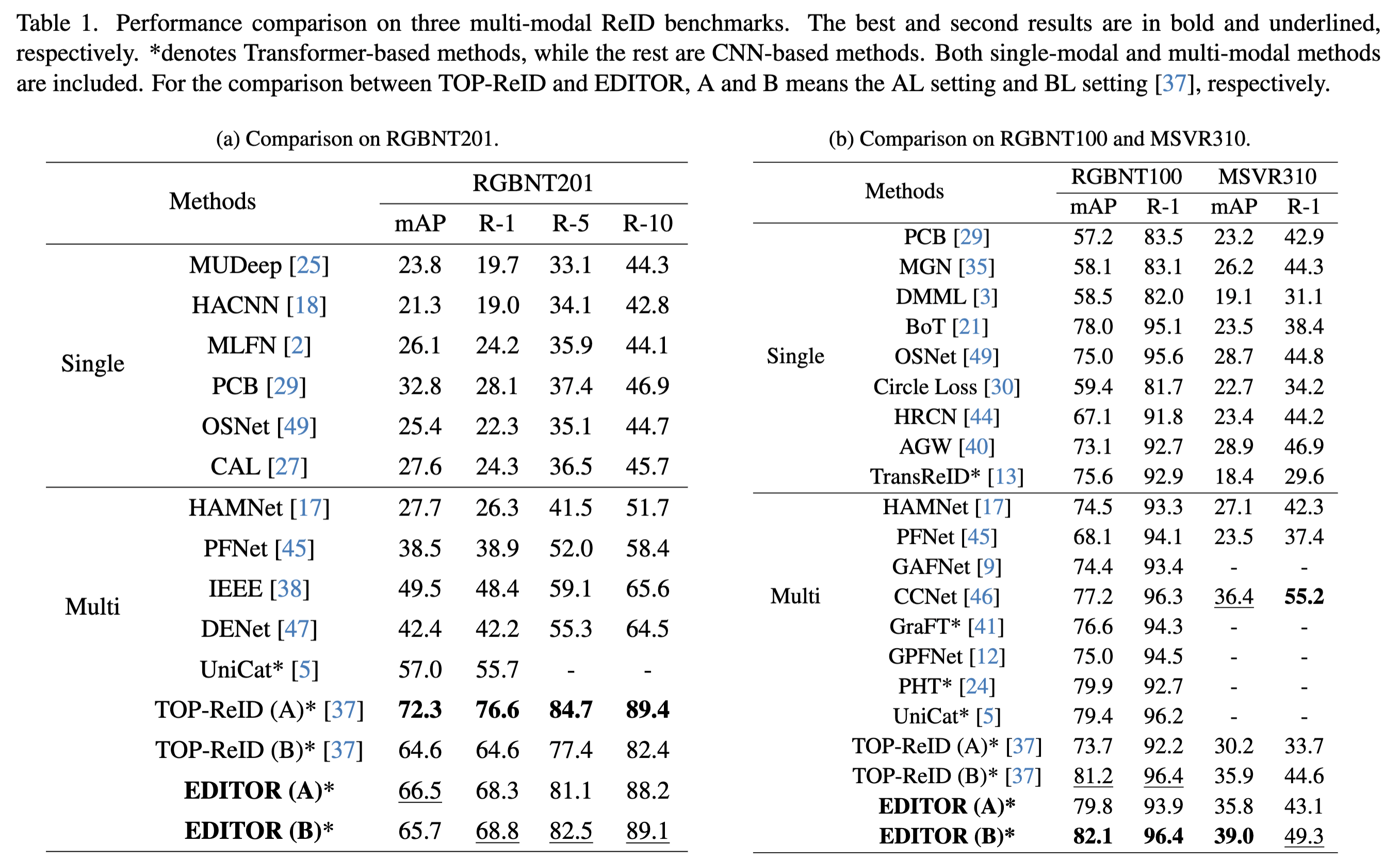
Single-modal object re-identification (ReID) faces great challenges in maintaining robustness within complex visual scenarios. In contrast, multi-modal object ReID utilizes complementary information from diverse modalities, showing great potentials for practical applications. However, previous methods may be easily affected by irrelevant backgrounds and usually ignore the modality gaps. To address above issues, we propose a novel learning framework named \textbf{EDITOR} to select diverse tokens from vision Transformers for multi-modal object ReID. We begin with a shared vision Transformer to extract tokenized features from different input modalities. Then, we introduce a Spatial-Frequency Token Selection (SFTS) module to adaptively select object-centric tokens with both spatial and frequency information. Afterwards, we employ a Hierarchical Masked Aggregation (HMA) module to facilitate feature interactions within and across modalities. Finally, to further reduce the effect of backgrounds, we propose a Background Consistency Constraint (BCC) and an Object-Centric Feature Refinement (OCFR). They are formulated as two new loss functions, which improve the feature discrimination with background suppression. As a result, our framework can generate more discriminative features for multi-modal object ReID. Extensive experiments on three multi-modal ReID benchmarks verify the effectiveness of our methods. The code is available at https://github.com/924973292/EDITOR.
PDF Abstract

