MinkLoc++: Lidar and Monocular Image Fusion for Place Recognition
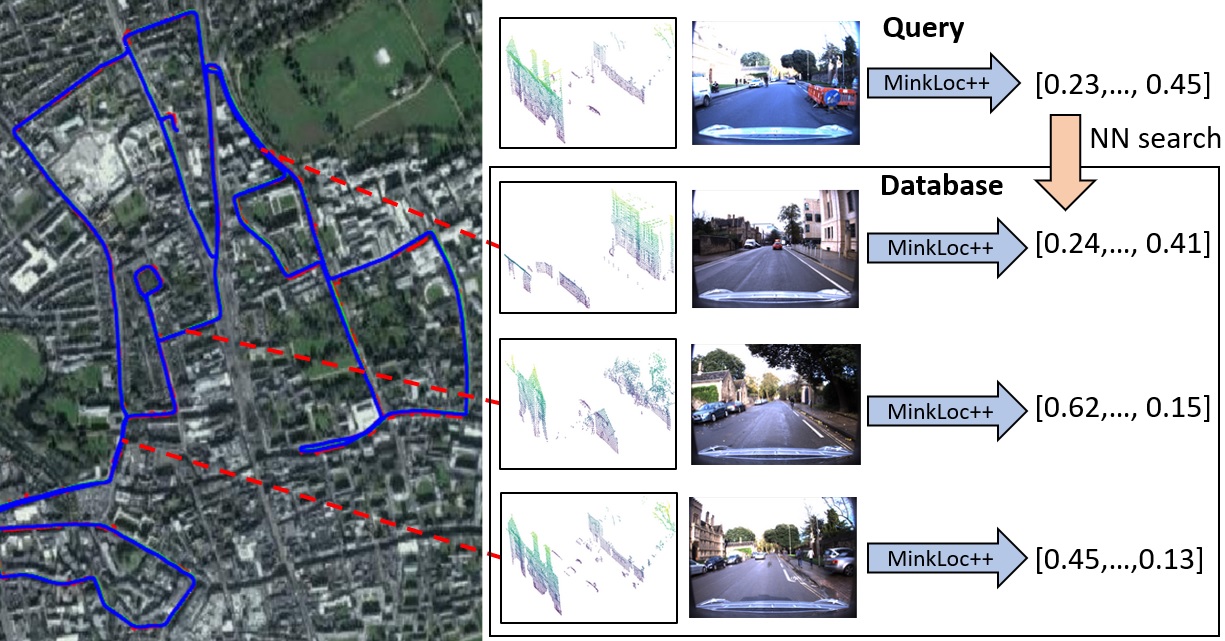
We introduce a discriminative multimodal descriptor based on a pair of sensor readings: a point cloud from a LiDAR and an image from an RGB camera. Our descriptor, named MinkLoc++, can be used for place recognition, re-localization and loop closure purposes in robotics or autonomous vehicles applications. We use late fusion approach, where each modality is processed separately and fused in the final part of the processing pipeline. The proposed method achieves state-of-the-art performance on standard place recognition benchmarks. We also identify dominating modality problem when training a multimodal descriptor. The problem manifests itself when the network focuses on a modality with a larger overfit to the training data. This drives the loss down during the training but leads to suboptimal performance on the evaluation set. In this work we describe how to detect and mitigate such risk when using a deep metric learning approach to train a multimodal neural network. Our code is publicly available on the project website: https://github.com/jac99/MinkLocMultimodal.
PDF Abstract




 KITTI
KITTI
 Oxford RobotCar Dataset
Oxford RobotCar Dataset

