ML-Bench: Evaluating Large Language Models for Code Generation in Repository-Level Machine Learning Tasks
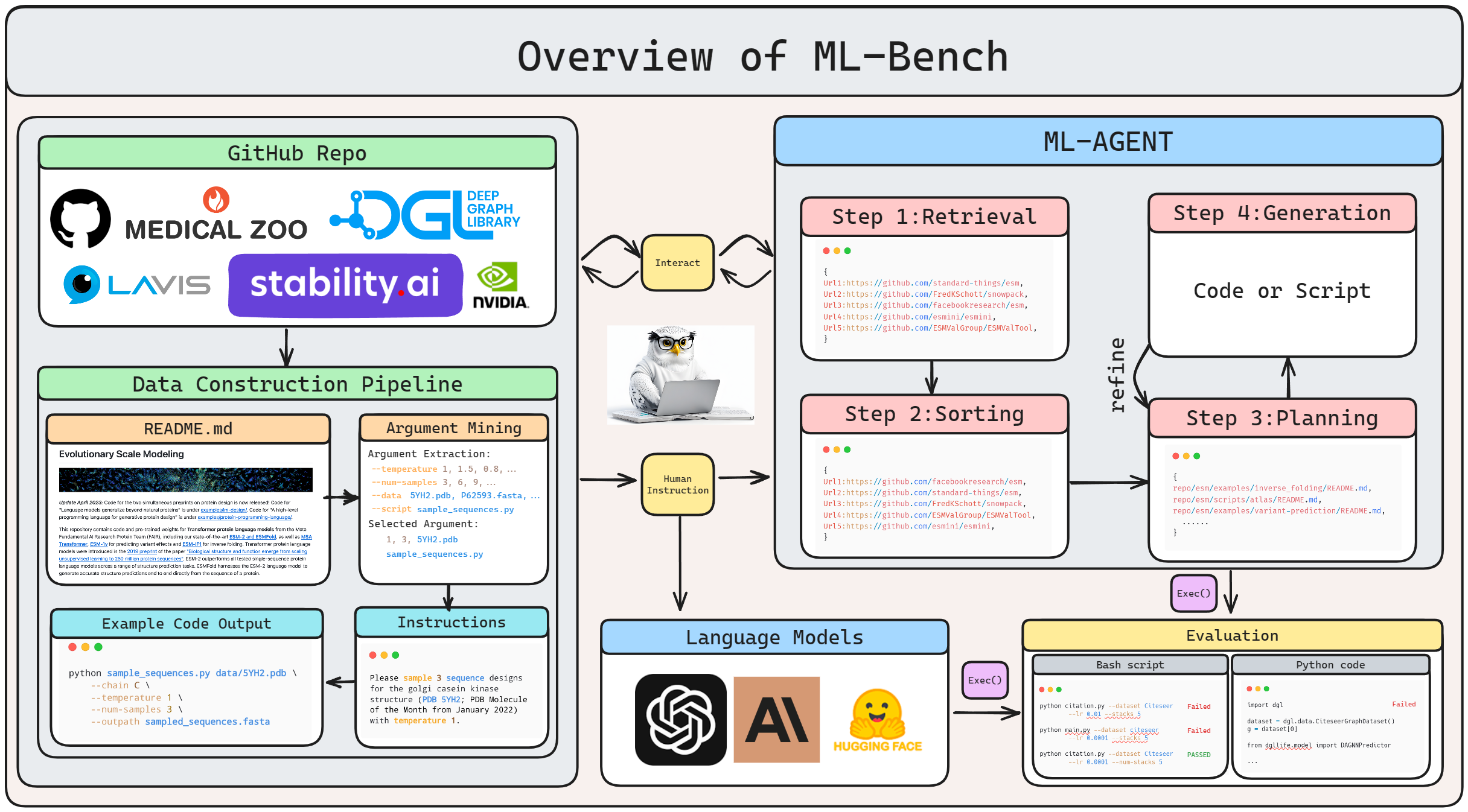
While Large Language Models (LLMs) have demonstrated proficiency in code generation benchmarks, translating these results into practical development scenarios - where leveraging existing repository-level libraries is the norm - remains challenging. To bridge the gap between lab-scale benchmarks and real-world coding practices, we introduce ML-Bench: a novel benchmark designed to assess LLMs' ability to integrate and utilize repository-level open-source libraries to complete machine learning tasks. ML-Bench comprises a diverse set of 9,641 samples across 169 distinct tasks derived from 18 GitHub repositories. Our findings reveal that while GPT-4 outshines other LLMs, it successfully addresses only 33.82% of the tasks, highlighting the complexity of the challenge. Complementarily, we introduce a baseline agent, ML-Agent, capable of skillful codebase navigation and precise generation of functional code segments. This groundwork aims at catalyzing the development of more sophisticated LLM agents that can handle the intricacies of real-world programming. Our code, data, and models are available at https://github.com/gersteinlab/ML-bench.
PDF Abstract


 HumanEval
HumanEval
