Multi-direction and Multi-scale Pyramid in Transformer for Video-based Pedestrian Retrieval
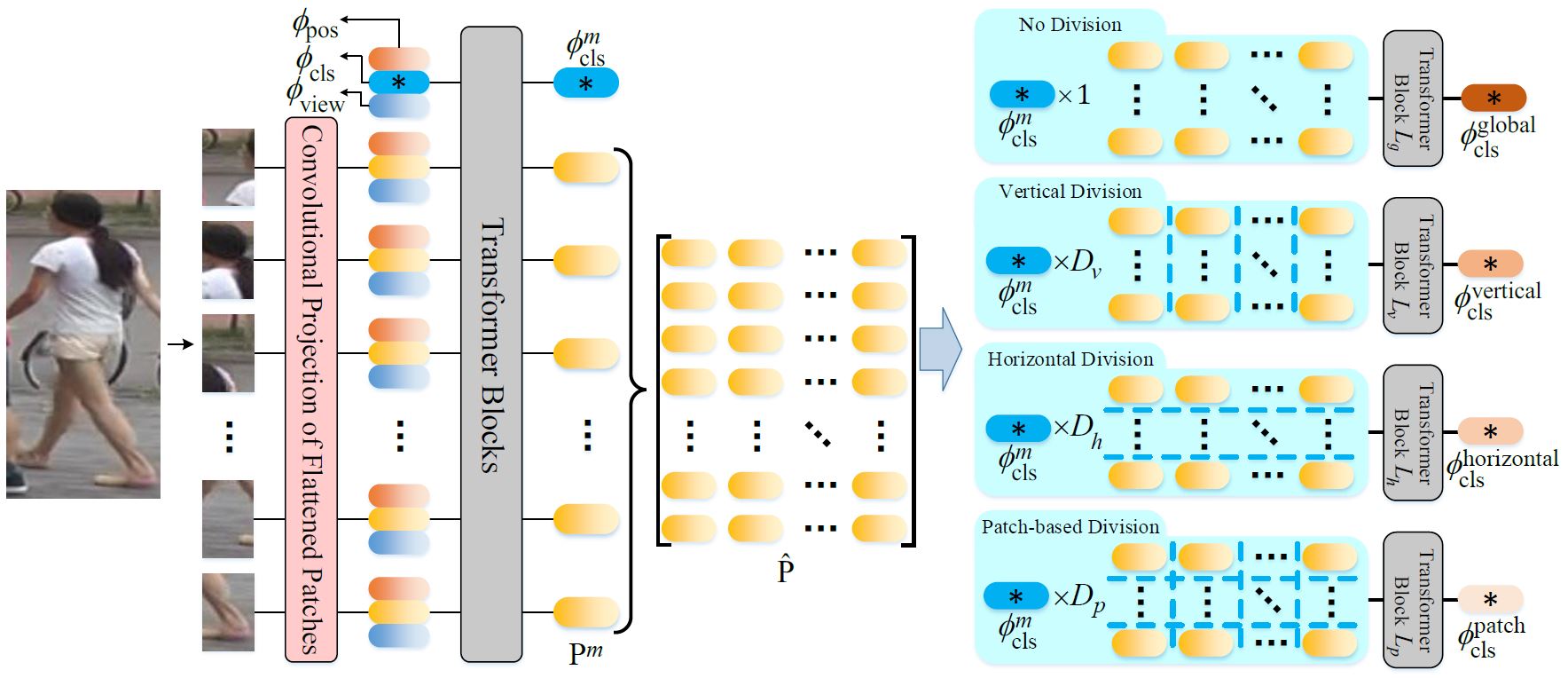
In video surveillance, pedestrian retrieval (also called person re-identification) is a critical task. This task aims to retrieve the pedestrian of interest from non-overlapping cameras. Recently, transformer-based models have achieved significant progress for this task. However, these models still suffer from ignoring fine-grained, part-informed information. This paper proposes a multi-direction and multi-scale Pyramid in Transformer (PiT) to solve this problem. In transformer-based architecture, each pedestrian image is split into many patches. Then, these patches are fed to transformer layers to obtain the feature representation of this image. To explore the fine-grained information, this paper proposes to apply vertical division and horizontal division on these patches to generate different-direction human parts. These parts provide more fine-grained information. To fuse multi-scale feature representation, this paper presents a pyramid structure containing global-level information and many pieces of local-level information from different scales. The feature pyramids of all the pedestrian images from the same video are fused to form the final multi-direction and multi-scale feature representation. Experimental results on two challenging video-based benchmarks, MARS and iLIDS-VID, show the proposed PiT achieves state-of-the-art performance. Extensive ablation studies demonstrate the superiority of the proposed pyramid structure. The code is available at https://git.openi.org.cn/zangxh/PiT.git.
PDF Abstract


 MARS
MARS
