Text-driven object affordance for guiding grasp-type recognition in multimodal robot teaching
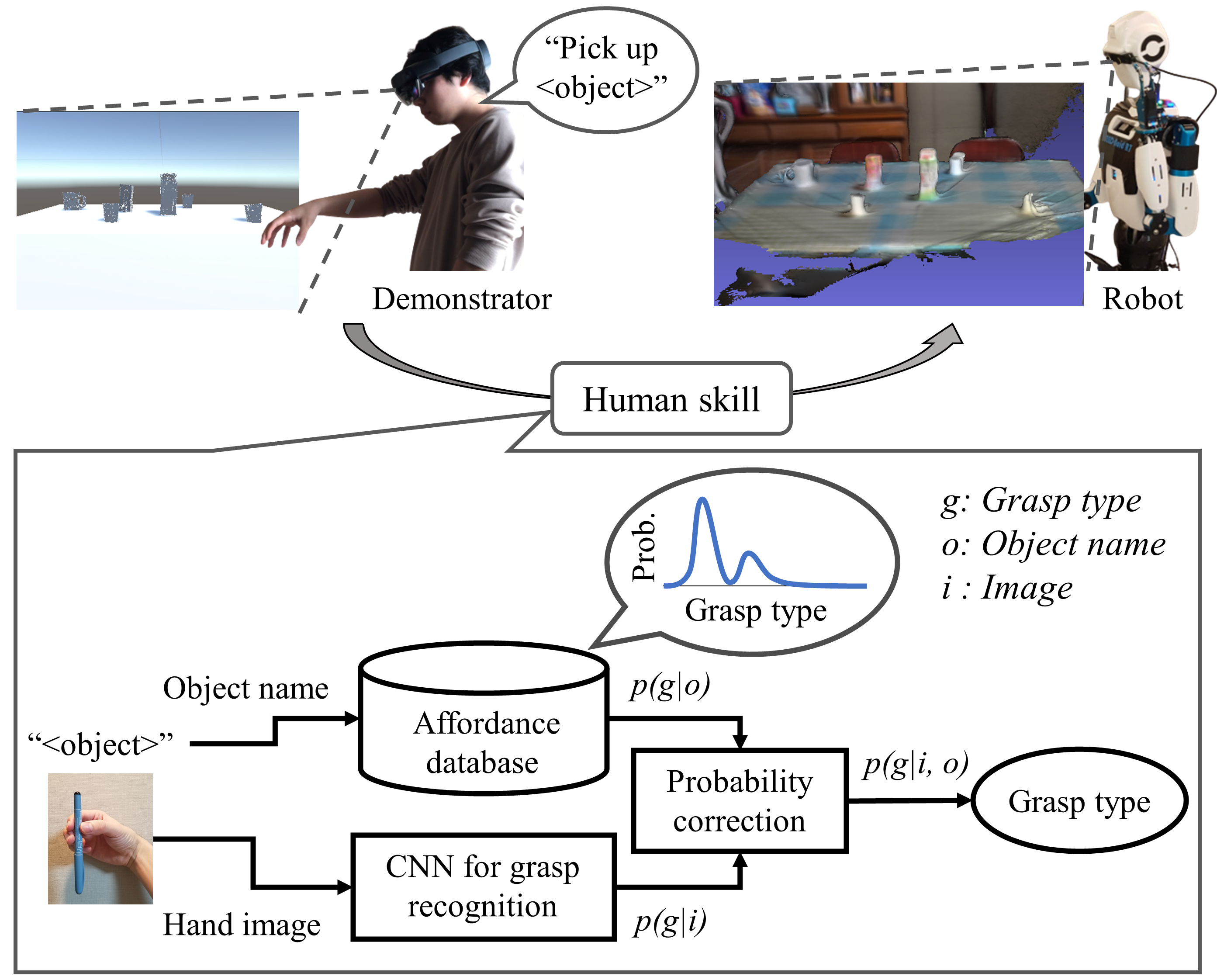
This study investigates how text-driven object affordance, which provides prior knowledge about grasp types for each object, affects image-based grasp-type recognition in robot teaching. The researchers created labeled datasets of first-person hand images to examine the impact of object affordance on recognition performance. They evaluated scenarios with real and illusory objects, considering mixed reality teaching conditions where visual object information may be limited. The results demonstrate that object affordance improves image-based recognition by filtering out unlikely grasp types and emphasizing likely ones. The effectiveness of object affordance was more pronounced when there was a stronger bias towards specific grasp types for each object. These findings highlight the significance of object affordance in multimodal robot teaching, regardless of whether real objects are present in the images. Sample code is available on https://github.com/microsoft/arr-grasp-type-recognition.
PDF Abstract

