Open-Vocabulary Universal Image Segmentation with MaskCLIP
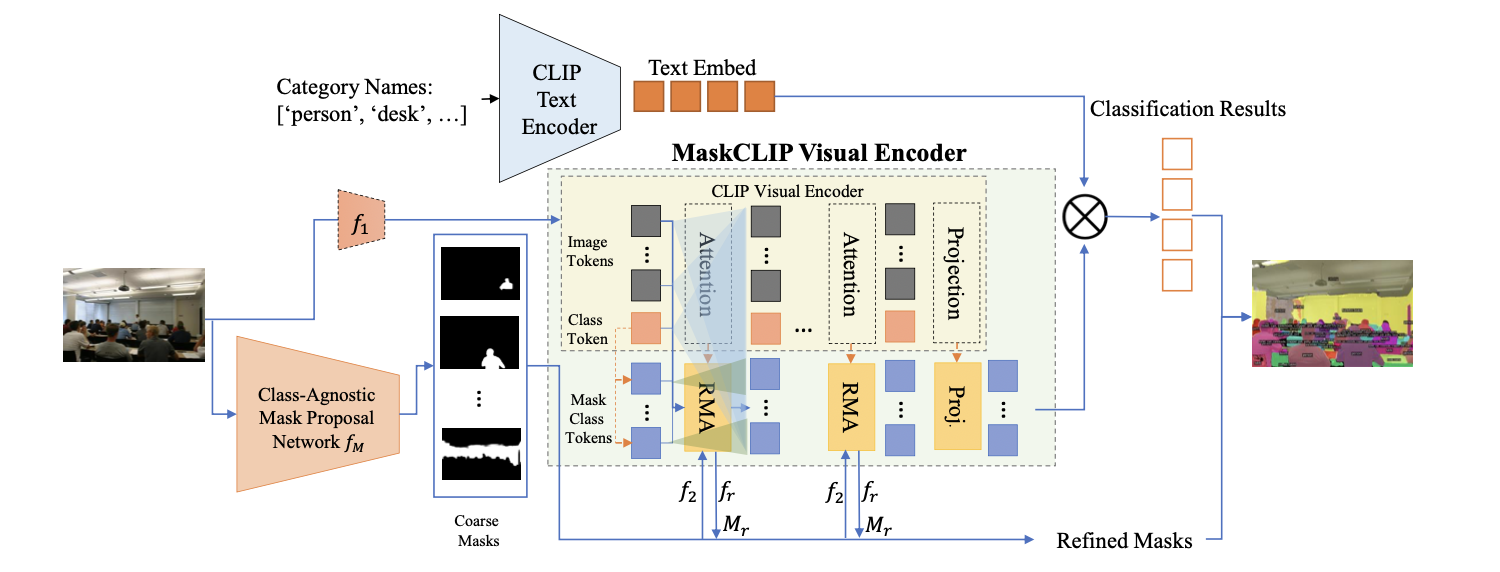
In this paper, we tackle an emerging computer vision task, open-vocabulary universal image segmentation, that aims to perform semantic/instance/panoptic segmentation (background semantic labeling + foreground instance segmentation) for arbitrary categories of text-based descriptions in inference time. We first build a baseline method by directly adopting pre-trained CLIP models without finetuning or distillation. We then develop MaskCLIP, a Transformer-based approach with a MaskCLIP Visual Encoder, which is an encoder-only module that seamlessly integrates mask tokens with a pre-trained ViT CLIP model for semantic/instance segmentation and class prediction. MaskCLIP learns to efficiently and effectively utilize pre-trained partial/dense CLIP features within the MaskCLIP Visual Encoder that avoids the time-consuming student-teacher training process. MaskCLIP outperforms previous methods for semantic/instance/panoptic segmentation on ADE20K and PASCAL datasets. We show qualitative illustrations for MaskCLIP with online custom categories. Project website: https://maskclip.github.io.
PDF Abstract




 MS COCO
MS COCO
 ADE20K
ADE20K
 PASCAL Context
PASCAL Context

