Pay Attention when Required
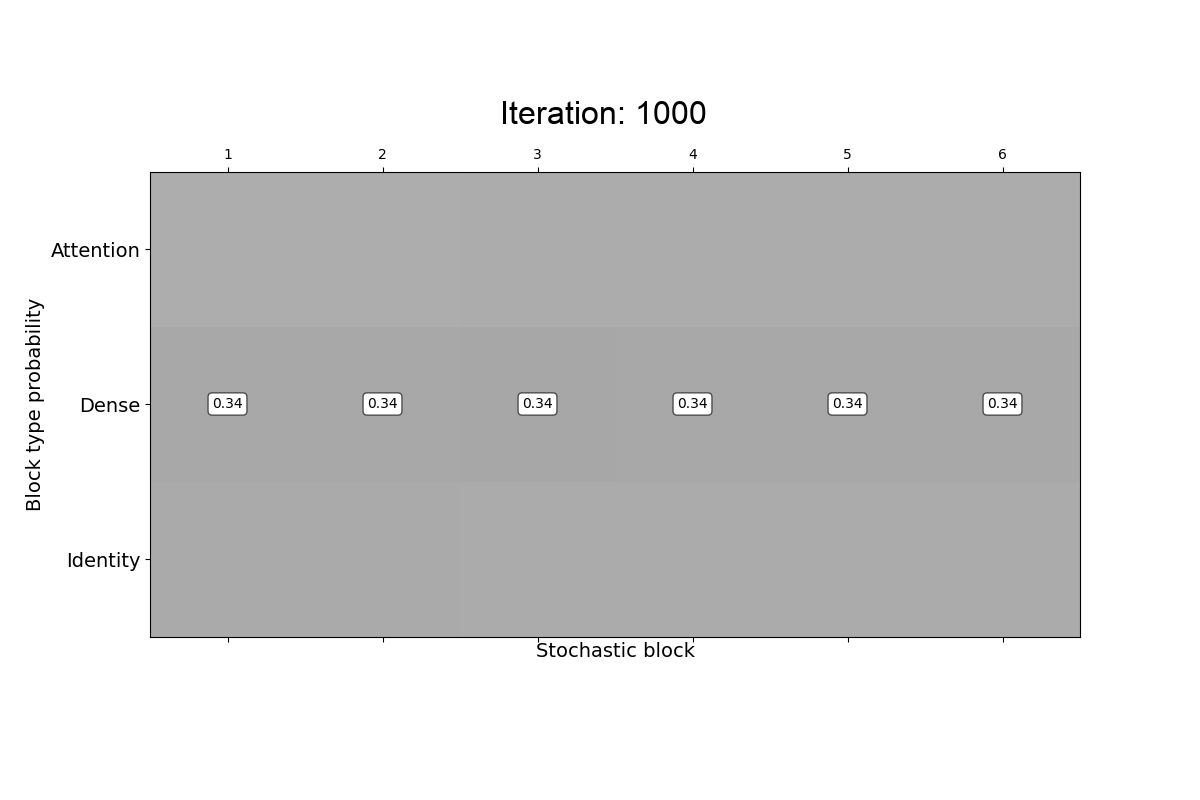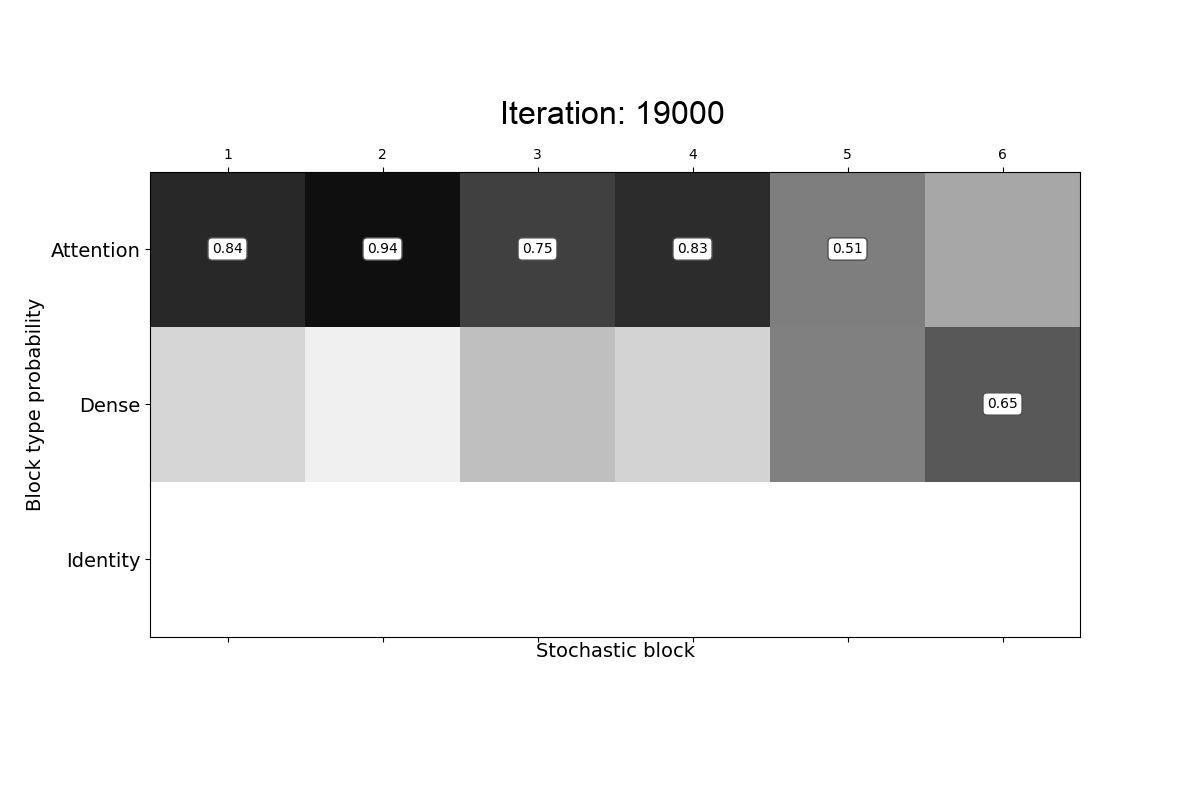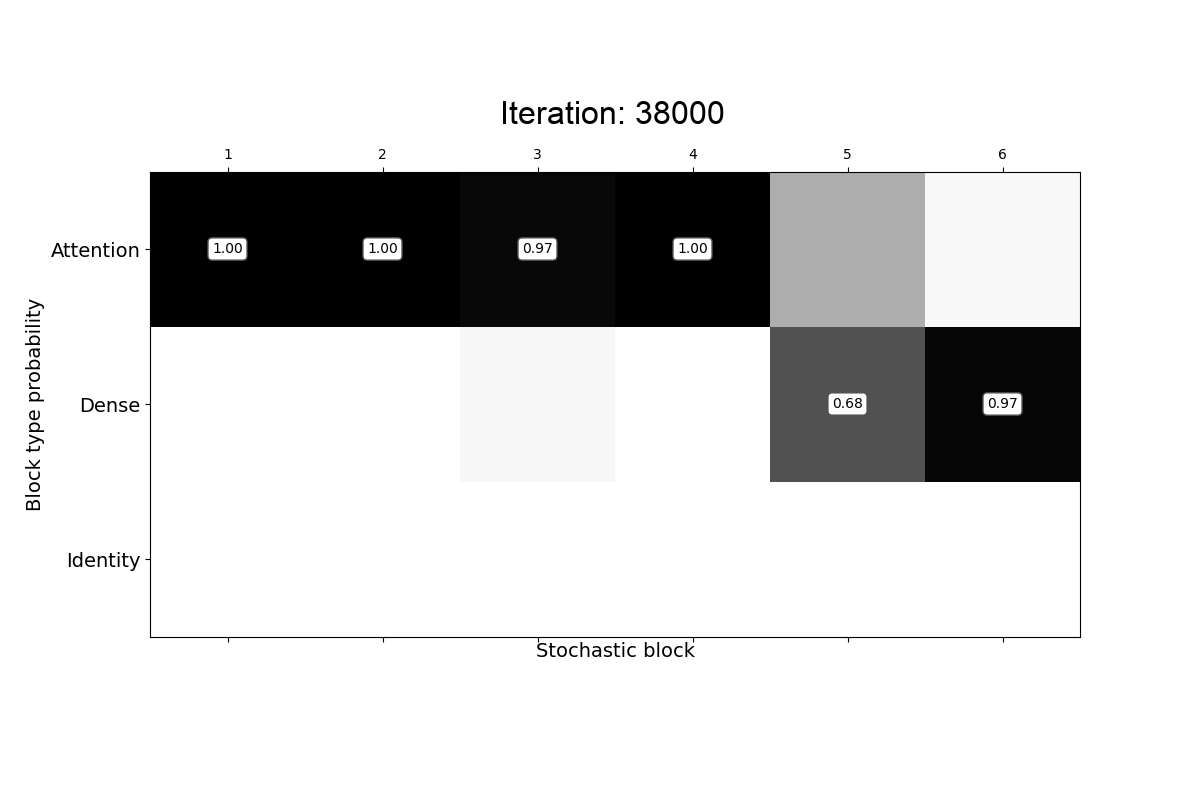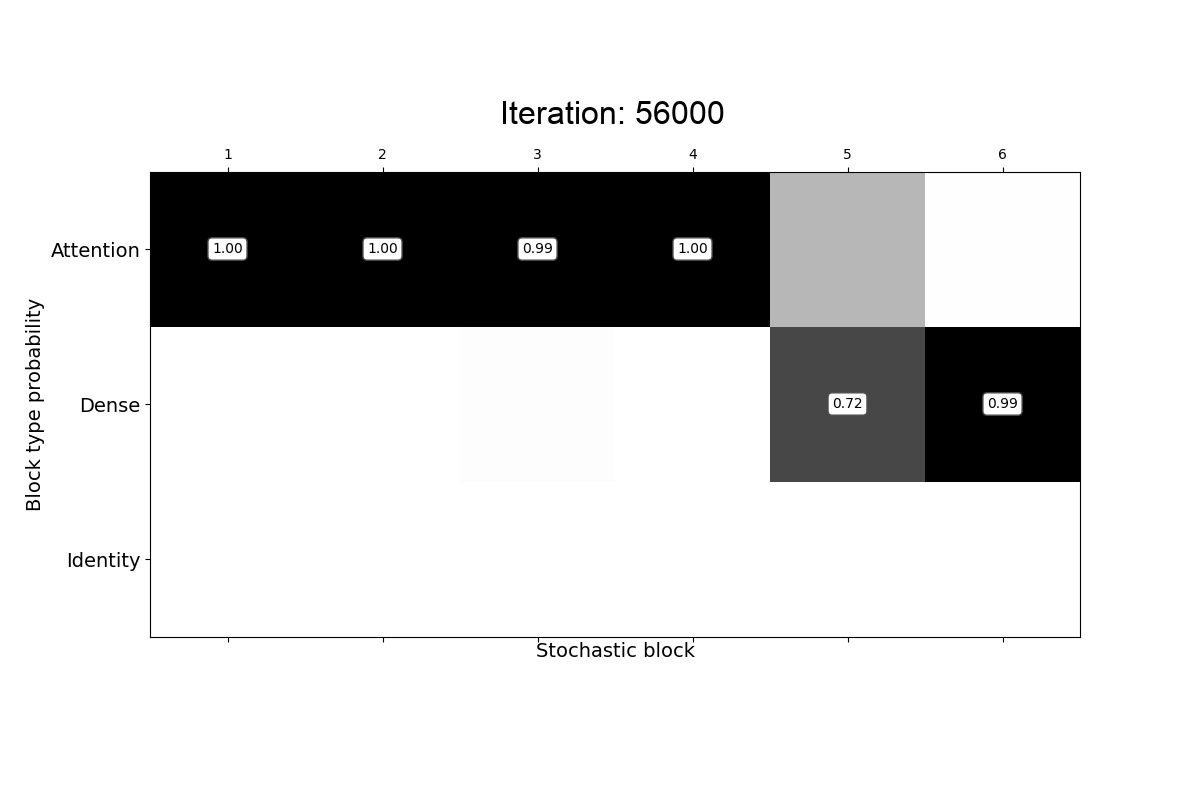
Transformer-based models consist of interleaved feed-forward blocks - that capture content meaning, and relatively more expensive self-attention blocks - that capture context meaning. In this paper, we explored trade-offs and ordering of the blocks to improve upon the current Transformer architecture and proposed PAR Transformer. It needs 35% lower compute time than Transformer-XL achieved by replacing ~63% of the self-attention blocks with feed-forward blocks, and retains the perplexity on WikiText-103 language modelling benchmark. We further validated our results on text8 and enwiki8 datasets, as well as on the BERT model.
PDF AbstractCode





Datasets
 GLUE
GLUE
 SST
SST
 SQuAD
SQuAD
 WikiText-2
WikiText-2
 WikiText-103
WikiText-103

Methods
Absolute Position Encodings •
Adam •
Adaptive Input Representations •
Adaptive Softmax •
Attention Dropout •
BERT •
BPE •
Cosine Annealing •
Dense Connections •
Dropout •
GELU •
Label Smoothing •
Layer Normalization •
Linear Layer •
Linear Warmup With Cosine Annealing •
Linear Warmup With Linear Decay •
Multi-Head Attention •
PAR Transformer •
Position-Wise Feed-Forward Layer •
ReLU •
Residual Connection •
Scaled Dot-Product Attention •
Softmax •
Transformer •
Transformer-XL •
Variational Dropout •
Weight Decay •
WordPiece
