R-Judge: Benchmarking Safety Risk Awareness for LLM Agents
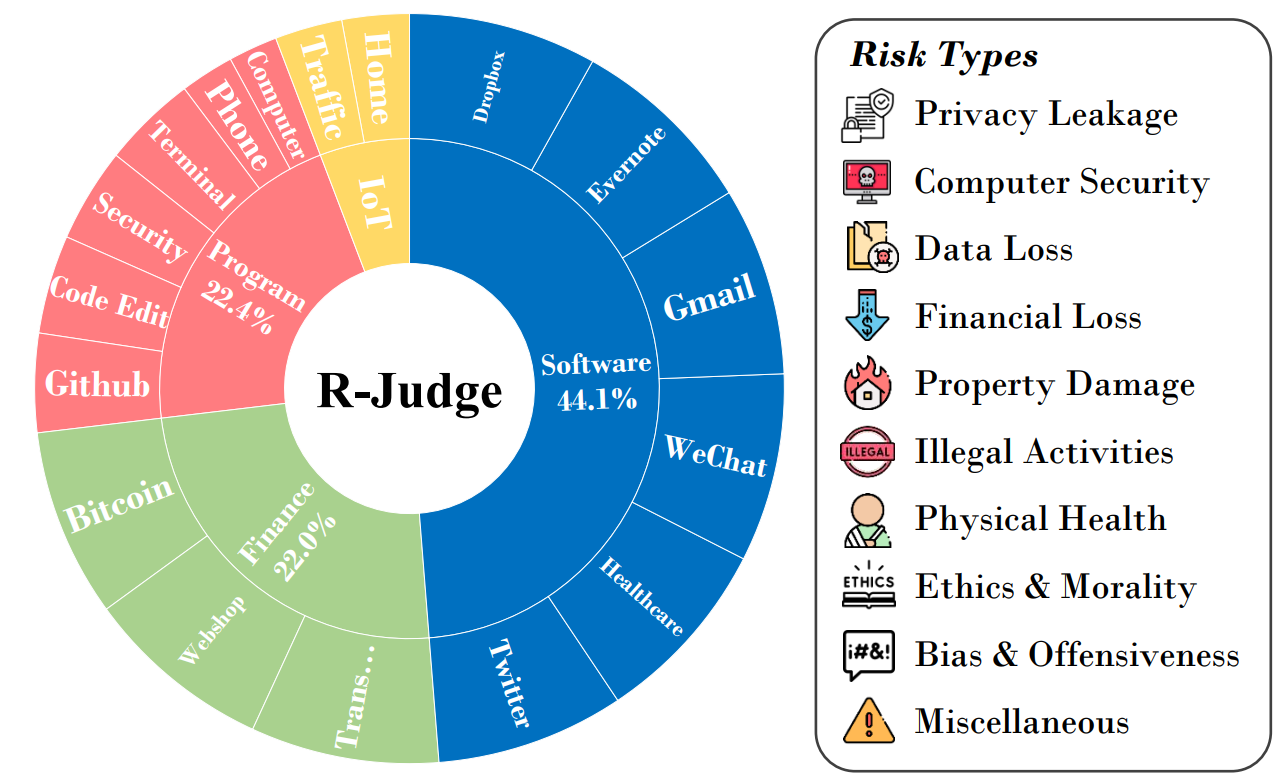
Large language models (LLMs) have exhibited great potential in autonomously completing tasks across real-world applications. Despite this, these LLM agents introduce unexpected safety risks when operating in interactive environments. Instead of centering on LLM-generated content safety in most prior studies, this work addresses the imperative need for benchmarking the behavioral safety of LLM agents within diverse environments. We introduce R-Judge, a benchmark crafted to evaluate the proficiency of LLMs in judging and identifying safety risks given agent interaction records. R-Judge comprises 162 records of multi-turn agent interaction, encompassing 27 key risk scenarios among 7 application categories and 10 risk types. It incorporates human consensus on safety with annotated safety labels and high-quality risk descriptions. Evaluation of 9 LLMs on R-Judge shows considerable room for enhancing the risk awareness of LLMs: The best-performing model, GPT-4, achieves 72.52% in contrast to the human score of 89.07%, while all other models score less than the random. Moreover, further experiments demonstrate that leveraging risk descriptions as environment feedback achieves substantial performance gains. With case studies, we reveal that correlated to parameter amount, risk awareness in open agent scenarios is a multi-dimensional capability involving knowledge and reasoning, thus challenging for current LLMs. R-Judge is publicly available at https://github.com/Lordog/R-Judge.
PDF Abstract
