Self-Ensembling Vision Transformer (SEViT) for Robust Medical Image Classification
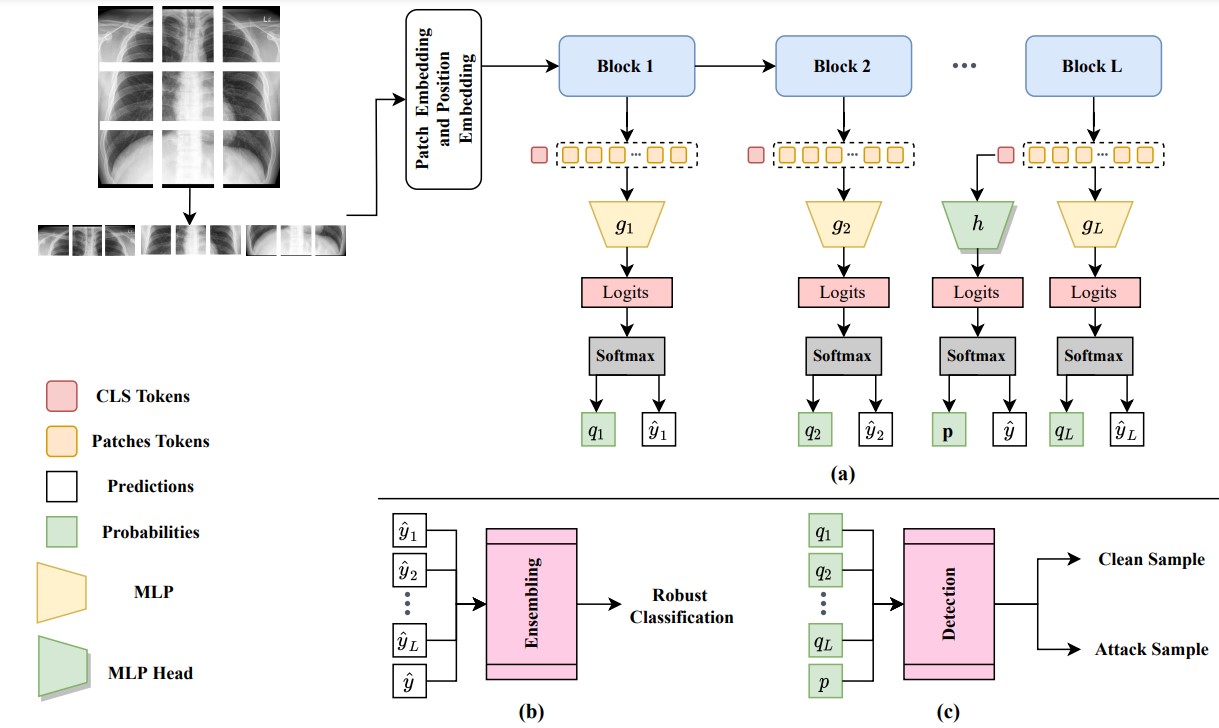
Vision Transformers (ViT) are competing to replace Convolutional Neural Networks (CNN) for various computer vision tasks in medical imaging such as classification and segmentation. While the vulnerability of CNNs to adversarial attacks is a well-known problem, recent works have shown that ViTs are also susceptible to such attacks and suffer significant performance degradation under attack. The vulnerability of ViTs to carefully engineered adversarial samples raises serious concerns about their safety in clinical settings. In this paper, we propose a novel self-ensembling method to enhance the robustness of ViT in the presence of adversarial attacks. The proposed Self-Ensembling Vision Transformer (SEViT) leverages the fact that feature representations learned by initial blocks of a ViT are relatively unaffected by adversarial perturbations. Learning multiple classifiers based on these intermediate feature representations and combining these predictions with that of the final ViT classifier can provide robustness against adversarial attacks. Measuring the consistency between the various predictions can also help detect adversarial samples. Experiments on two modalities (chest X-ray and fundoscopy) demonstrate the efficacy of SEViT architecture to defend against various adversarial attacks in the gray-box (attacker has full knowledge of the target model, but not the defense mechanism) setting. Code: https://github.com/faresmalik/SEViT
PDF Abstract


