Self-Supervised Visual Preference Alignment
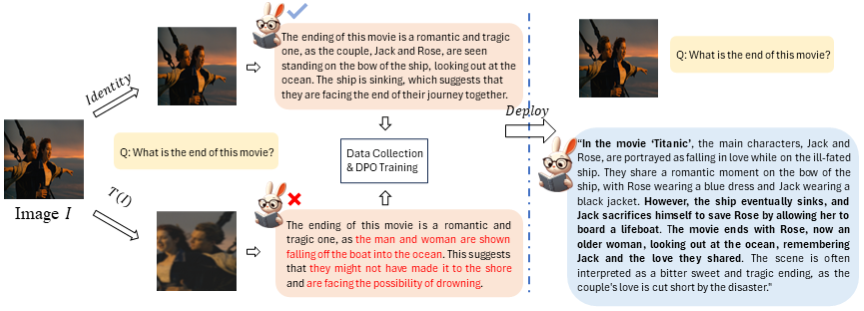
This paper makes the first attempt towards unsupervised preference alignment in Vision-Language Models (VLMs). We generate chosen and rejected responses with regard to the original and augmented image pairs, and conduct preference alignment with direct preference optimization. It is based on a core idea: properly designed augmentation to the image input will induce VLM to generate false but hard negative responses, which helps the model to learn from and produce more robust and powerful answers. The whole pipeline no longer hinges on supervision from GPT4 or human involvement during alignment, and is highly efficient with few lines of code. With only 8k randomly sampled unsupervised data, it achieves 90\% relative score to GPT-4 on complex reasoning in LLaVA-Bench, and improves LLaVA-7B/13B by 6.7\%/5.6\% score on complex multi-modal benchmark MM-Vet. Visualizations shows its improved ability to align with user-intentions. A series of ablations are firmly conducted to reveal the latent mechanism of the approach, which also indicates its potential towards further scaling. Code will be available.
PDF Abstract

 GQA
GQA
 TextVQA
TextVQA
 MMBench
MMBench
 MM-Vet
MM-Vet

