Spatial-Assistant Encoder-Decoder Network for Real Time Semantic Segmentation
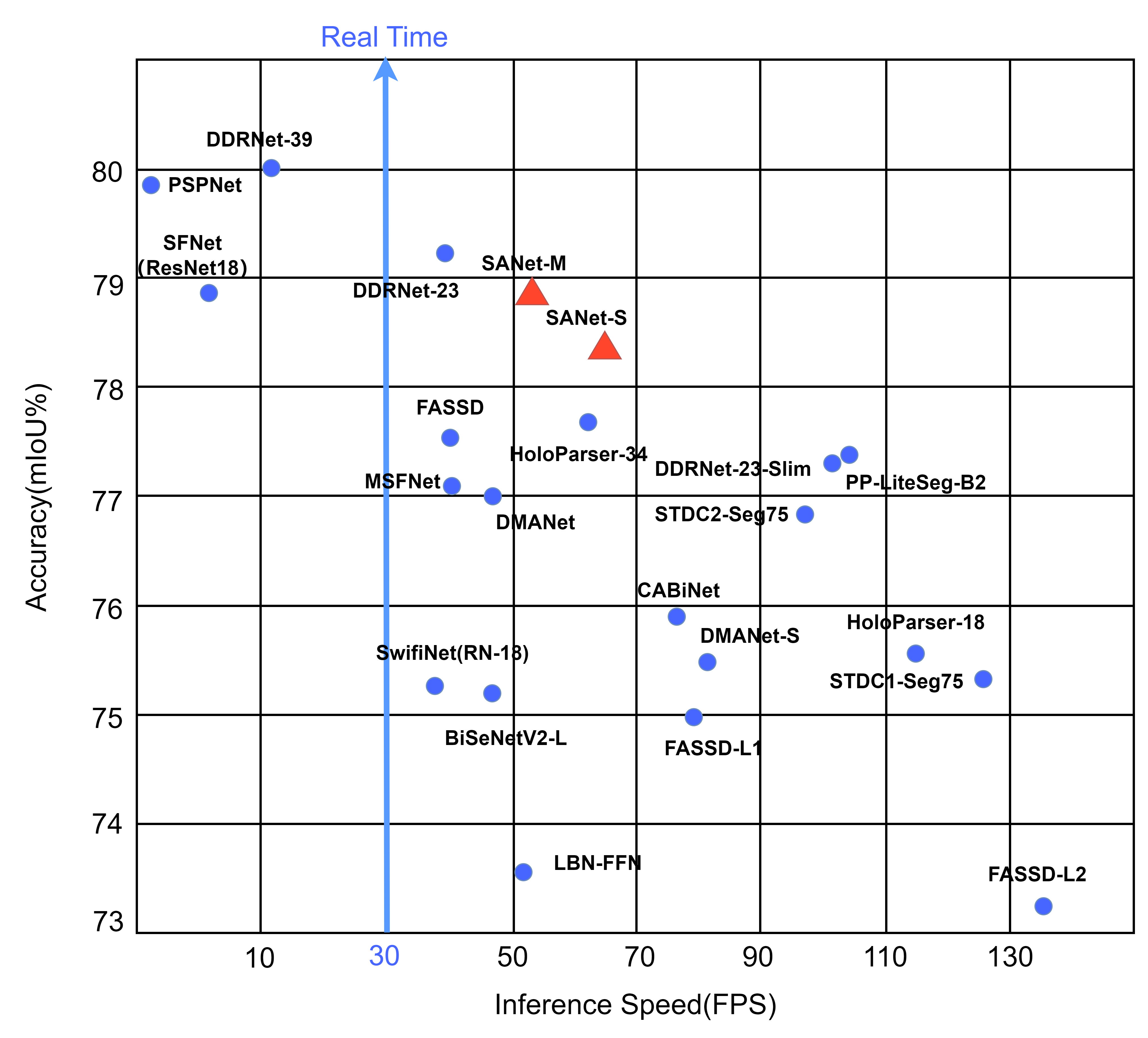
Semantic segmentation is an essential technology for self-driving cars to comprehend their surroundings. Currently, real-time semantic segmentation networks commonly employ either encoder-decoder architecture or two-pathway architecture. Generally speaking, encoder-decoder models tend to be quicker,whereas two-pathway models exhibit higher accuracy. To leverage both strengths, we present the Spatial-Assistant Encoder-Decoder Network (SANet) to fuse the two architectures. In the overall architecture, we uphold the encoder-decoder design while maintaining the feature maps in the middle section of the encoder and utilizing atrous convolution branches for same-resolution feature extraction. Toward the end of the encoder, we integrate the asymmetric pooling pyramid pooling module (APPPM) to optimize the semantic extraction of the feature maps. This module incorporates asymmetric pooling layers that extract features at multiple resolutions. In the decoder, we present a hybrid attention module, SAD, that integrates horizontal and vertical attention to facilitate the combination of various branches. To ascertain the effectiveness of our approach, our SANet model achieved competitive results on the real-time CamVid and cityscape datasets. By employing a single 2080Ti GPU, SANet achieved a 78.4 % mIOU at 65.1 FPS on the Cityscape test dataset and 78.8 % mIOU at 147 FPS on the CamVid test dataset. The training code and model for SANet are available at https://github.com/CuZaoo/SANet-main
PDF Abstract




 Cityscapes
Cityscapes
 CamVid
CamVid
