SwinNet: Swin Transformer drives edge-aware RGB-D and RGB-T salient object detection
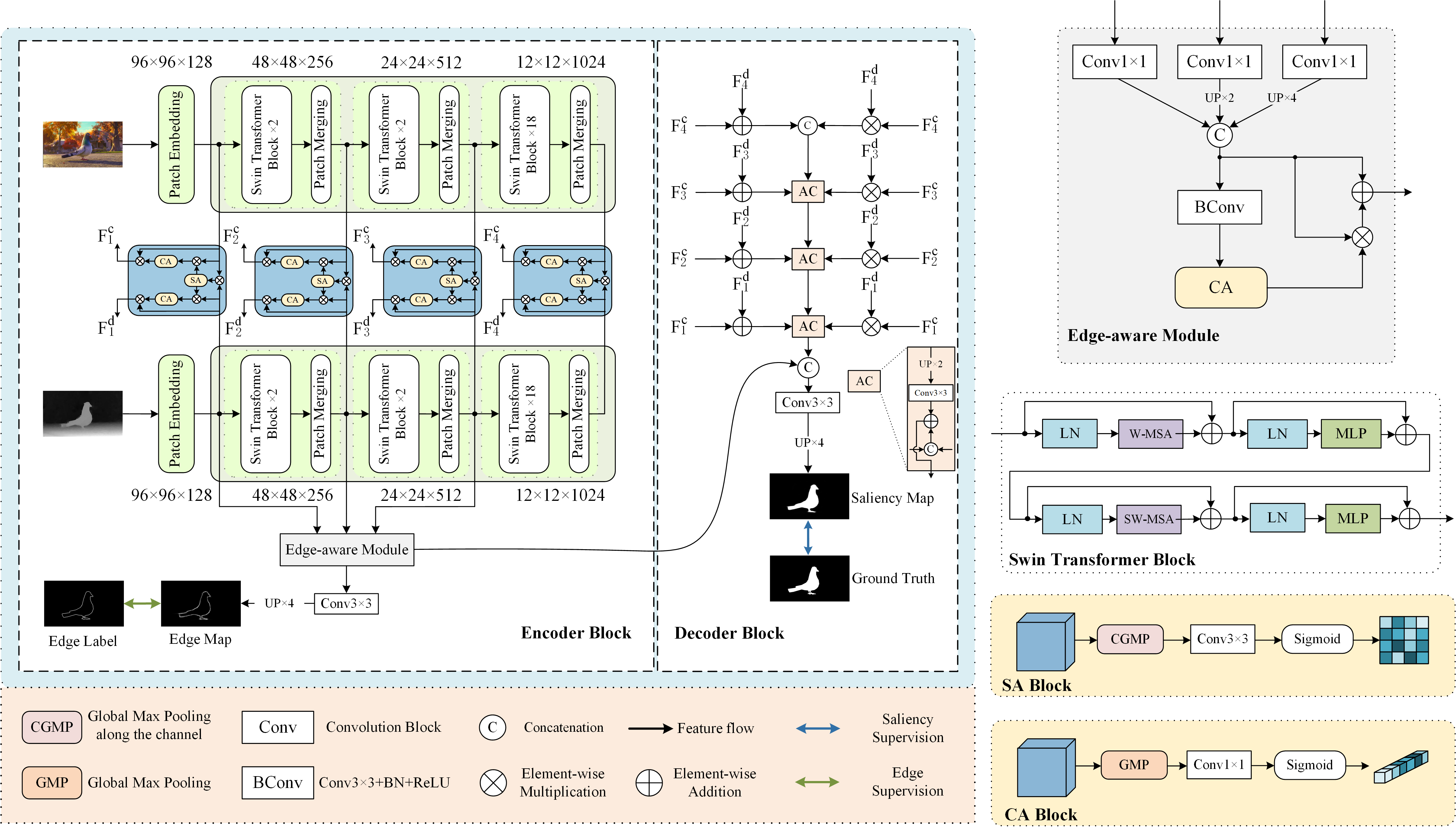
Convolutional neural networks (CNNs) are good at extracting contexture features within certain receptive fields, while transformers can model the global long-range dependency features. By absorbing the advantage of transformer and the merit of CNN, Swin Transformer shows strong feature representation ability. Based on it, we propose a cross-modality fusion model SwinNet for RGB-D and RGB-T salient object detection. It is driven by Swin Transformer to extract the hierarchical features, boosted by attention mechanism to bridge the gap between two modalities, and guided by edge information to sharp the contour of salient object. To be specific, two-stream Swin Transformer encoder first extracts multi-modality features, and then spatial alignment and channel re-calibration module is presented to optimize intra-level cross-modality features. To clarify the fuzzy boundary, edge-guided decoder achieves inter-level cross-modality fusion under the guidance of edge features. The proposed model outperforms the state-of-the-art models on RGB-D and RGB-T datasets, showing that it provides more insight into the cross-modality complementarity task.
PDF Abstract


 NLPR
NLPR
 SIP
SIP
 NJU2K
NJU2K
