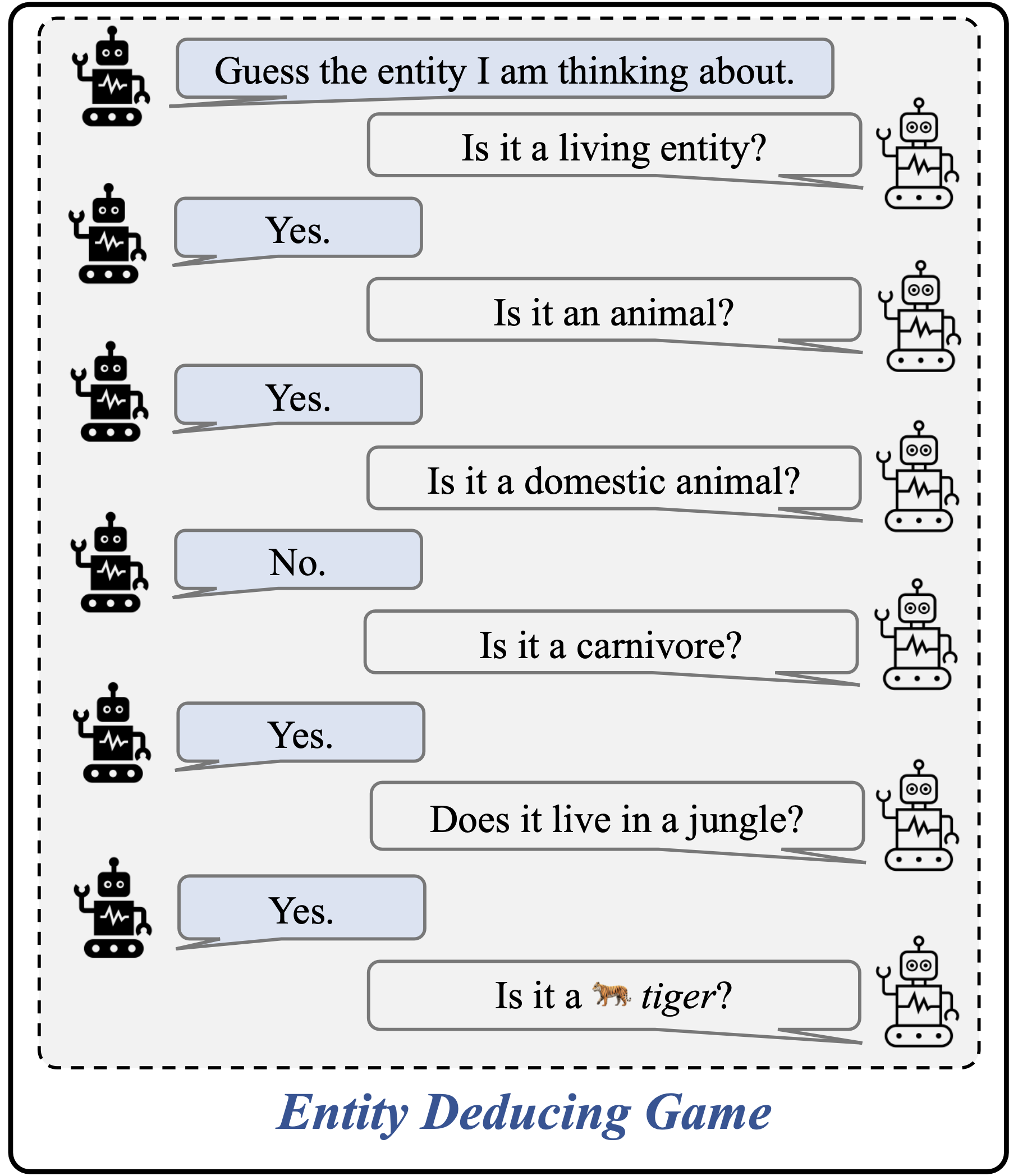
Probing the Multi-turn Planning Capabilities of LLMs via 20 Question Games
Large language models (LLMs) are effective at answering questions that are clearly asked. However, when faced with ambiguous queries they can act unpredictably and produce incorrect outputs. This underscores the need for the development of intelligent agents capable of asking clarification questions to resolve ambiguities effectively. This capability requires complex understanding, state tracking, reasoning and planning over multiple conversational turns. However, directly measuring this can be challenging. In this paper, we offer a surrogate problem which assesses an LLMs's capability to deduce an entity unknown to itself, but revealed to a judge, by asking the judge a series of queries. This \textit{entity-deducing game} can serve as an evaluation framework to probe the conversational reasoning and planning capabilities of language models. We systematically evaluate various LLMs and discover significant differences in their performance on this task. We find that strong LLMs like GPT-4 outperform human players by a large margin. We further employ Behavior Cloning (BC) to examine whether a weaker model is capable of imitating a stronger model and generalizing to data or domains, using only the demonstrations from a stronger model. We finally propose to use Reinforcement Learning to enhance reasoning and planning capacity of Vicuna models through episodes of game playing, which lead to significant performance improvement. We hope that this problem offers insights into how autonomous agents could be trained to behave more intelligently in ambiguous circumstances.
PDF Abstract
