Tracking Anything in High Quality
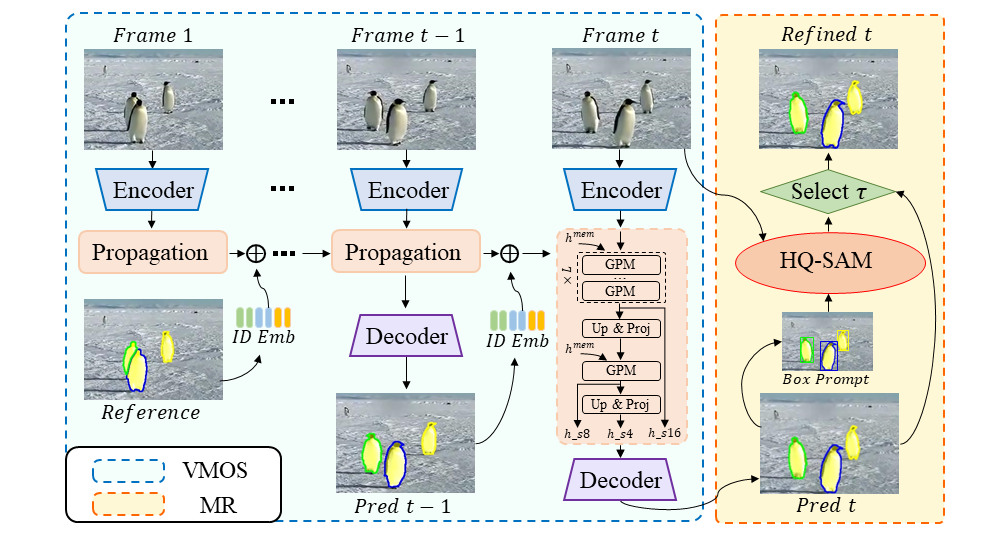
Visual object tracking is a fundamental video task in computer vision. Recently, the notably increasing power of perception algorithms allows the unification of single/multiobject and box/mask-based tracking. Among them, the Segment Anything Model (SAM) attracts much attention. In this report, we propose HQTrack, a framework for High Quality Tracking anything in videos. HQTrack mainly consists of a video multi-object segmenter (VMOS) and a mask refiner (MR). Given the object to be tracked in the initial frame of a video, VMOS propagates the object masks to the current frame. The mask results at this stage are not accurate enough since VMOS is trained on several closeset video object segmentation (VOS) datasets, which has limited ability to generalize to complex and corner scenes. To further improve the quality of tracking masks, a pretrained MR model is employed to refine the tracking results. As a compelling testament to the effectiveness of our paradigm, without employing any tricks such as test-time data augmentations and model ensemble, HQTrack ranks the 2nd place in the Visual Object Tracking and Segmentation (VOTS2023) challenge. Code and models are available at https://github.com/jiawen-zhu/HQTrack.
PDF AbstractCode






Datasets
 YouTube-VOS 2018
YouTube-VOS 2018
 OVIS
OVIS
Results from the Paper
 Ranked #5 on
Semi-Supervised Video Object Segmentation
on YouTube-VOS 2019
(using extra training data)
Ranked #5 on
Semi-Supervised Video Object Segmentation
on YouTube-VOS 2019
(using extra training data)
