TRAM: Benchmarking Temporal Reasoning for Large Language Models
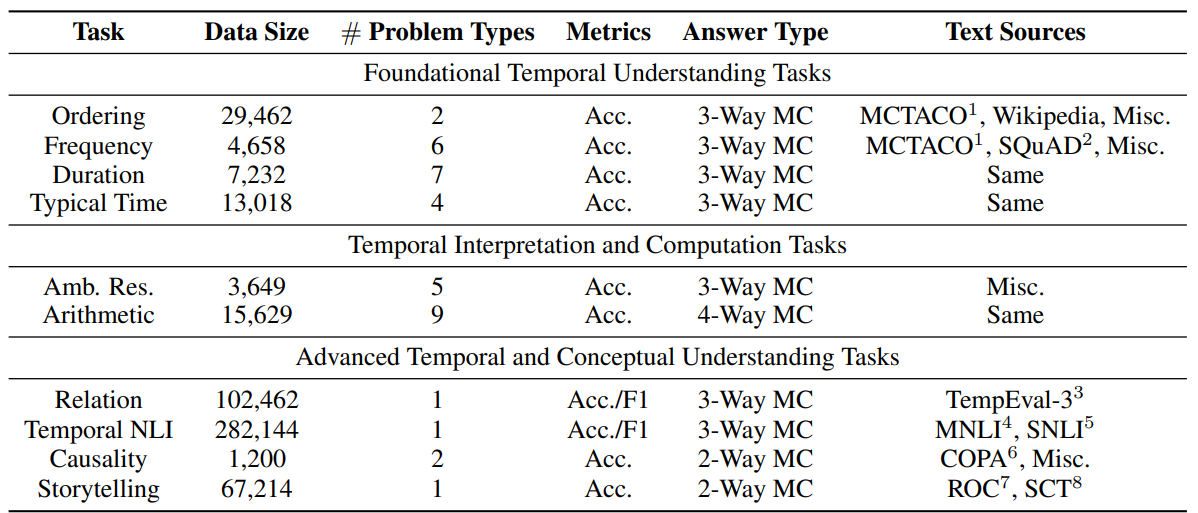
Reasoning about time is essential for understanding the nuances of events described in natural language. Previous research on this topic has been limited in scope, characterized by a lack of standardized benchmarks that would allow for consistent evaluations across different studies. In this paper, we introduce TRAM, a temporal reasoning benchmark composed of ten datasets, encompassing various temporal aspects of events such as order, arithmetic, frequency, and duration, designed to facilitate a comprehensive evaluation of the temporal reasoning capabilities of large language models (LLMs). We conduct an extensive evaluation using popular LLMs, such as GPT-4 and Llama2, in both zero-shot and few-shot learning scenarios. Additionally, we employ BERT-based models to establish the baseline evaluations. Our findings indicate that these models still trail human performance in temporal reasoning tasks. It is our aspiration that TRAM will spur further progress in enhancing the temporal reasoning abilities of LLMs.
PDF Abstract
