Visual Prompt Tuning
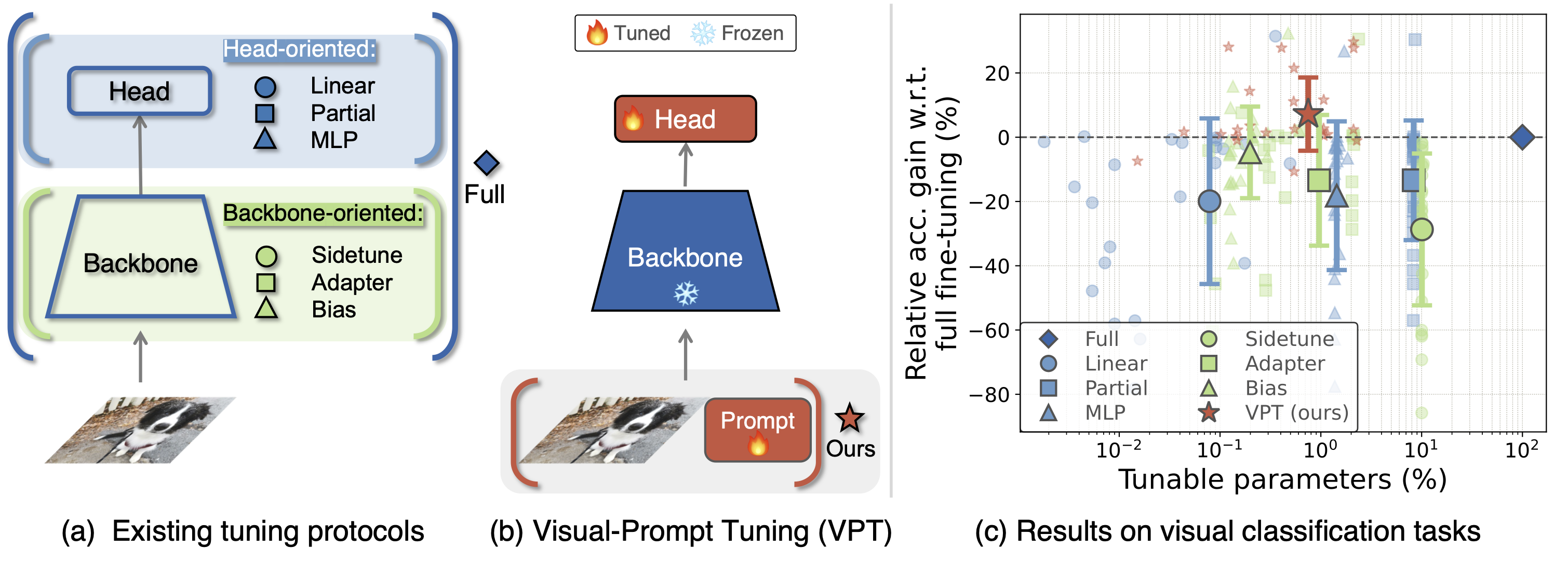
The current modus operandi in adapting pre-trained models involves updating all the backbone parameters, ie, full fine-tuning. This paper introduces Visual Prompt Tuning (VPT) as an efficient and effective alternative to full fine-tuning for large-scale Transformer models in vision. Taking inspiration from recent advances in efficiently tuning large language models, VPT introduces only a small amount (less than 1% of model parameters) of trainable parameters in the input space while keeping the model backbone frozen. Via extensive experiments on a wide variety of downstream recognition tasks, we show that VPT achieves significant performance gains compared to other parameter efficient tuning protocols. Most importantly, VPT even outperforms full fine-tuning in many cases across model capacities and training data scales, while reducing per-task storage cost.
PDF Abstract



 ImageNet
ImageNet
 CIFAR-100
CIFAR-100
 SVHN
SVHN
 Oxford 102 Flower
Oxford 102 Flower
 DTD
DTD
 EuroSAT
EuroSAT
 RESISC45
RESISC45
 NABirds
NABirds

