 Board Game Models
Board Game Models
AlphaZero
Introduced by Silver et al. in Mastering Chess and Shogi by Self-Play with a General Reinforcement Learning AlgorithmAlphaZero is a reinforcement learning agent for playing board games such as Go, chess, and shogi.
Source: Mastering Chess and Shogi by Self-Play with a General Reinforcement Learning Algorithm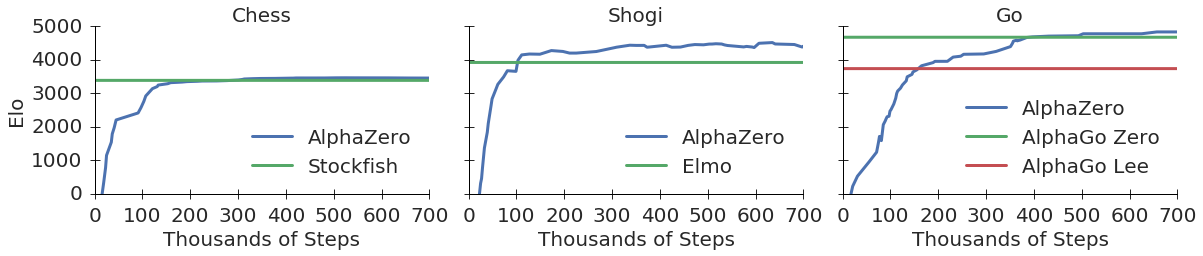
Papers
| Paper | Code | Results | Date | Stars |
|---|
Tasks
| Task | Papers | Share |
|---|---|---|
| Reinforcement Learning (RL) | 22 | 23.91% |
| Board Games | 19 | 20.65% |
| Game of Go | 8 | 8.70% |
| Decision Making | 7 | 7.61% |
| Atari Games | 7 | 7.61% |
| Game of Chess | 6 | 6.52% |
| Self-Learning | 2 | 2.17% |
| Combinatorial Optimization | 2 | 2.17% |
| Multi-agent Reinforcement Learning | 2 | 2.17% |
Usage Over Time
Components
| Component | Type |
|
|---|---|---|
| 🤖 No Components Found | You can add them if they exist; e.g. Mask R-CNN uses RoIAlign |
