
ByT5: Towards a token-free future with pre-trained byte-to-byte models
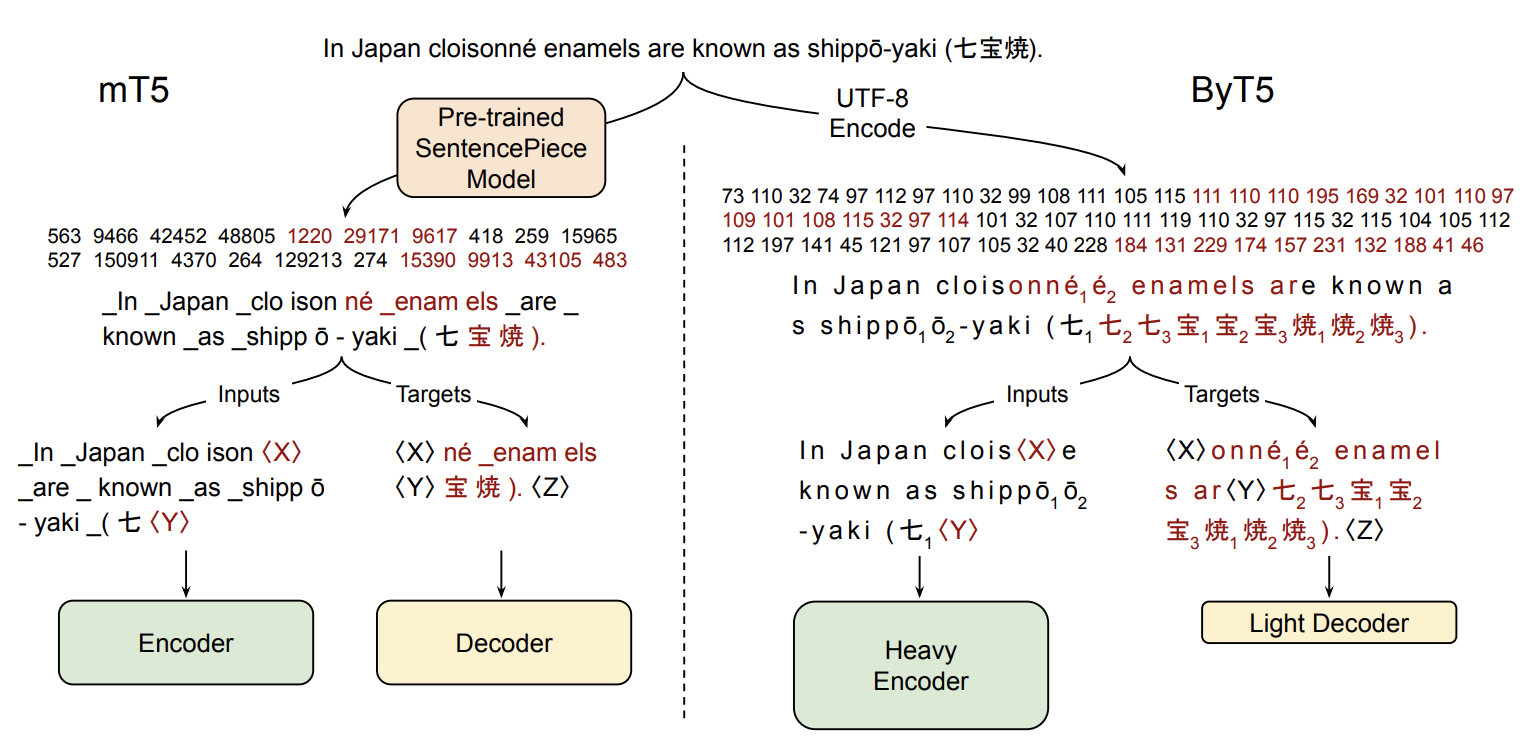
Most widely-used pre-trained language models operate on sequences of tokens corresponding to word or subword units. By comparison, token-free models that operate directly on raw text (bytes or characters) have many benefits: they can process text in any language out of the box, they are more robust to noise, and they minimize technical debt by removing complex and error-prone text preprocessing pipelines. Since byte or character sequences are longer than token sequences, past work on token-free models has often introduced new model architectures designed to amortize the cost of operating directly on raw text. In this paper, we show that a standard Transformer architecture can be used with minimal modifications to process byte sequences. We characterize the trade-offs in terms of parameter count, training FLOPs, and inference speed, and show that byte-level models are competitive with their token-level counterparts. We also demonstrate that byte-level models are significantly more robust to noise and perform better on tasks that are sensitive to spelling and pronunciation. As part of our contribution, we release a new set of pre-trained byte-level Transformer models based on the T5 architecture, as well as all code and data used in our experiments.
PDF Abstract

 Colab
Colab





 GLUE
GLUE
 C4
C4
 XNLI
XNLI
 DROP
DROP
 XQuAD
XQuAD
 PAWS-X
PAWS-X
 TyDiQA
TyDiQA
 MLQA
MLQA
 XTREME
XTREME
 GEM
GEM
 TyDiQA-GoldP
TyDiQA-GoldP
 TweetQA
TweetQA
 Dakshina
Dakshina

