CLIP-guided Prototype Modulating for Few-shot Action Recognition
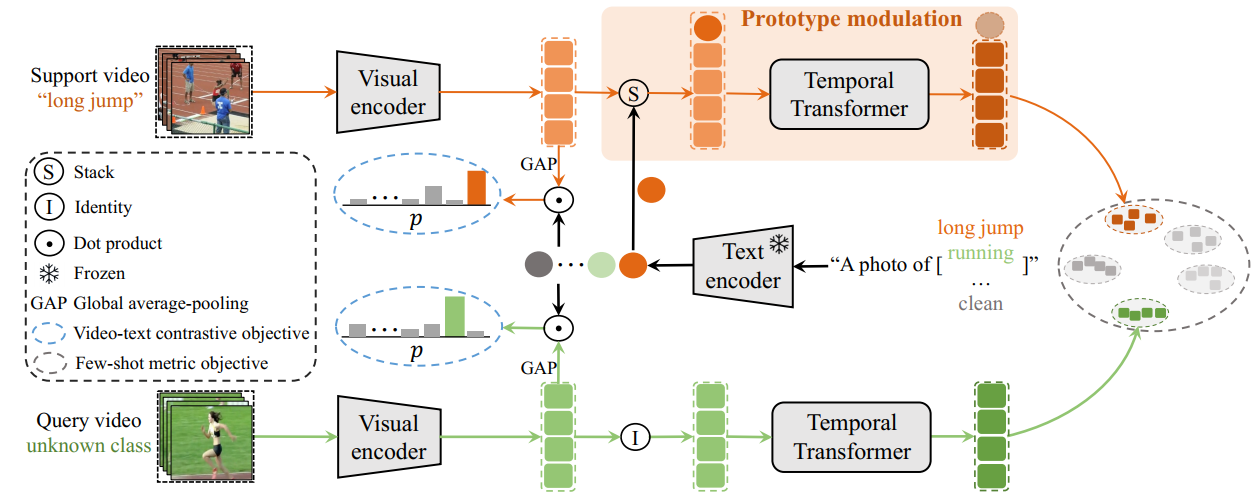
Learning from large-scale contrastive language-image pre-training like CLIP has shown remarkable success in a wide range of downstream tasks recently, but it is still under-explored on the challenging few-shot action recognition (FSAR) task. In this work, we aim to transfer the powerful multimodal knowledge of CLIP to alleviate the inaccurate prototype estimation issue due to data scarcity, which is a critical problem in low-shot regimes. To this end, we present a CLIP-guided prototype modulating framework called CLIP-FSAR, which consists of two key components: a video-text contrastive objective and a prototype modulation. Specifically, the former bridges the task discrepancy between CLIP and the few-shot video task by contrasting videos and corresponding class text descriptions. The latter leverages the transferable textual concepts from CLIP to adaptively refine visual prototypes with a temporal Transformer. By this means, CLIP-FSAR can take full advantage of the rich semantic priors in CLIP to obtain reliable prototypes and achieve accurate few-shot classification. Extensive experiments on five commonly used benchmarks demonstrate the effectiveness of our proposed method, and CLIP-FSAR significantly outperforms existing state-of-the-art methods under various settings. The source code and models will be publicly available at https://github.com/alibaba-mmai-research/CLIP-FSAR.
PDF Abstract


 ImageNet
ImageNet
 UCF101
UCF101
 HMDB51
HMDB51
