DeepSeekMath: Pushing the Limits of Mathematical Reasoning in Open Language Models
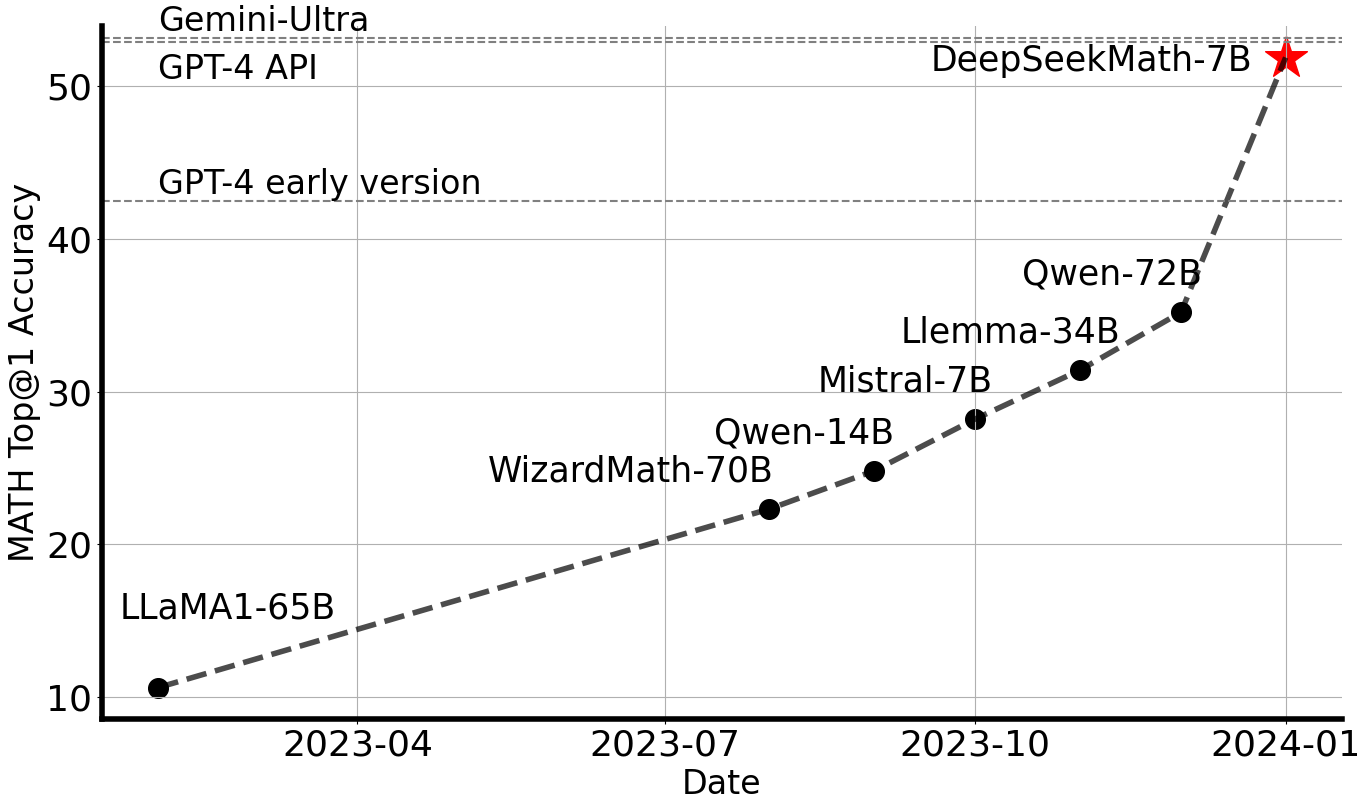
Mathematical reasoning poses a significant challenge for language models due to its complex and structured nature. In this paper, we introduce DeepSeekMath 7B, which continues pre-training DeepSeek-Coder-Base-v1.5 7B with 120B math-related tokens sourced from Common Crawl, together with natural language and code data. DeepSeekMath 7B has achieved an impressive score of 51.7% on the competition-level MATH benchmark without relying on external toolkits and voting techniques, approaching the performance level of Gemini-Ultra and GPT-4. Self-consistency over 64 samples from DeepSeekMath 7B achieves 60.9% on MATH. The mathematical reasoning capability of DeepSeekMath is attributed to two key factors: First, we harness the significant potential of publicly available web data through a meticulously engineered data selection pipeline. Second, we introduce Group Relative Policy Optimization (GRPO), a variant of Proximal Policy Optimization (PPO), that enhances mathematical reasoning abilities while concurrently optimizing the memory usage of PPO.
PDF AbstractCode
 Replicate
Replicate



 MMLU
MMLU
 GSM8K
GSM8K
 HumanEval
HumanEval
 MATH
MATH
 MiniF2F
MiniF2F
Results from the Paper
 Ranked #11 on
Math Word Problem Solving
on MATH
(using extra training data)
Ranked #11 on
Math Word Problem Solving
on MATH
(using extra training data)
| Task | Dataset | Model | Metric Name | Metric Value | Global Rank | Uses Extra Training Data |
Benchmark |
|---|---|---|---|---|---|---|---|
| Arithmetic Reasoning | GSM8K | DeepSeekMATH-RL-7B | Accuracy | 88.2 | # 27 | ||
| Parameters (Billion) | 7 | # 10 | |||||
| Math Word Problem Solving | MATH | DeepSeekMATH-RL-7B (w/ code, greedy decoding) | Accuracy | 58.8 | # 11 | ||
| Parameters (Billions) | 7 | # 58 | |||||
| Math Word Problem Solving | MATH | DeepSeekMATH-RL-7B (greedy decoding) | Accuracy | 51.7 | # 23 | ||
| Parameters (Billions) | 7 | # 58 |
