Dynamic Focus-aware Positional Queries for Semantic Segmentation
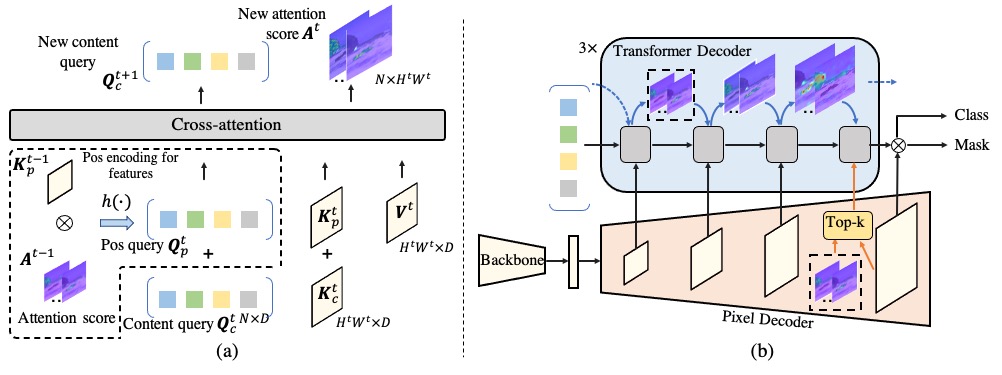
The DETR-like segmentors have underpinned the most recent breakthroughs in semantic segmentation, which end-to-end train a set of queries representing the class prototypes or target segments. Recently, masked attention is proposed to restrict each query to only attend to the foreground regions predicted by the preceding decoder block for easier optimization. Although promising, it relies on the learnable parameterized positional queries which tend to encode the dataset statistics, leading to inaccurate localization for distinct individual queries. In this paper, we propose a simple yet effective query design for semantic segmentation termed Dynamic Focus-aware Positional Queries (DFPQ), which dynamically generates positional queries conditioned on the cross-attention scores from the preceding decoder block and the positional encodings for the corresponding image features, simultaneously. Therefore, our DFPQ preserves rich localization information for the target segments and provides accurate and fine-grained positional priors. In addition, we propose to efficiently deal with high-resolution cross-attention by only aggregating the contextual tokens based on the low-resolution cross-attention scores to perform local relation aggregation. Extensive experiments on ADE20K and Cityscapes show that with the two modifications on Mask2former, our framework achieves SOTA performance and outperforms Mask2former by clear margins of 1.1%, 1.9%, and 1.1% single-scale mIoU with ResNet-50, Swin-T, and Swin-B backbones on the ADE20K validation set, respectively. Source code is available at https://github.com/ziplab/FASeg
PDF Abstract CVPR 2023 PDF CVPR 2023 Abstract

 Cityscapes
Cityscapes
 ADE20K
ADE20K

