Factcheck-Bench: Fine-Grained Evaluation Benchmark for Automatic Fact-checkers
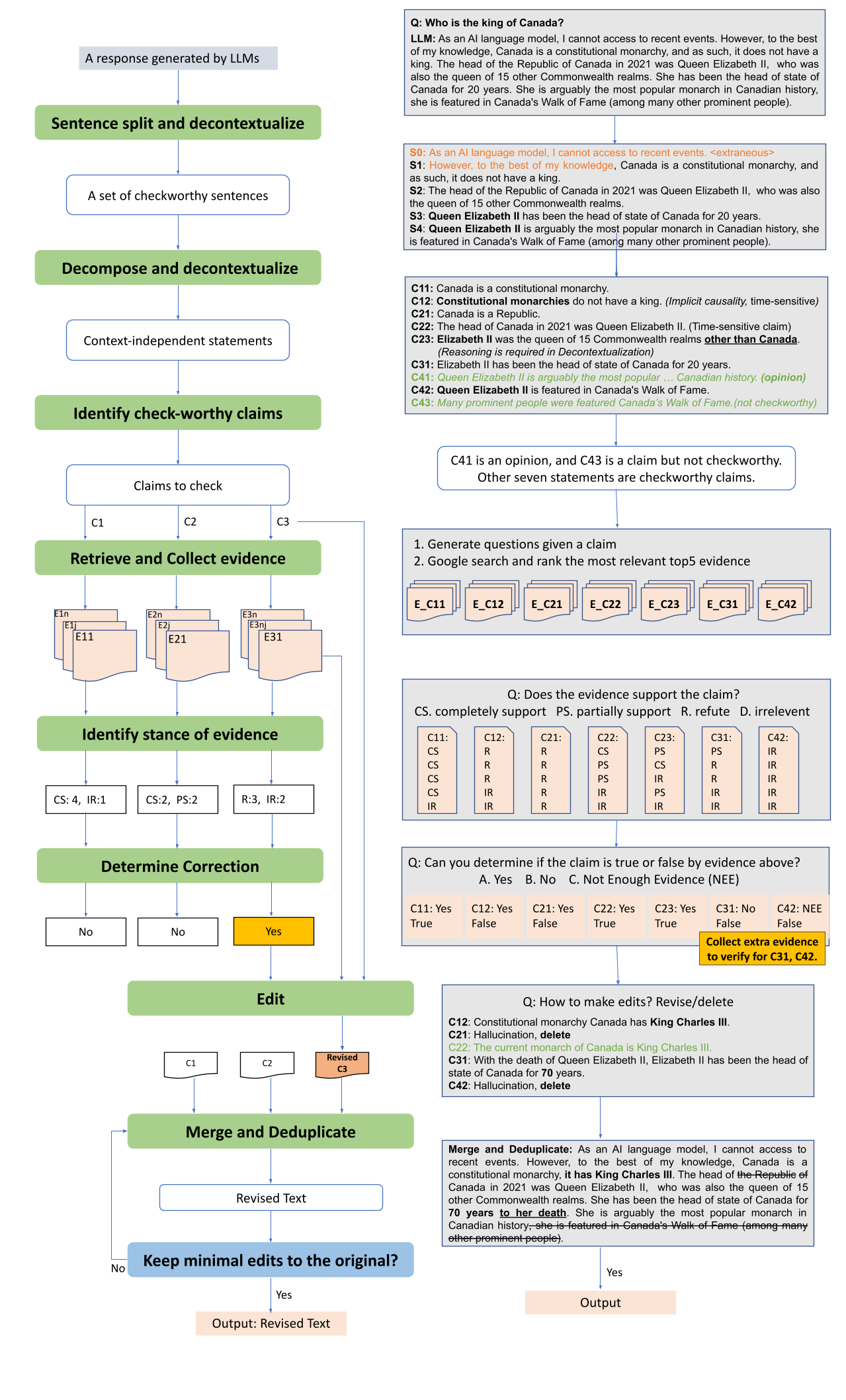
The increased use of large language models (LLMs) across a variety of real-world applications calls for mechanisms to verify the factual accuracy of their outputs. In this work, we present a holistic end-to-end solution for annotating the factuality of LLM-generated responses, which encompasses a multi-stage annotation scheme designed to yield detailed labels concerning the verifiability and factual inconsistencies found in LLM outputs. We further construct an open-domain document-level factuality benchmark in three-level granularity: claim, sentence and document, aiming to facilitate the evaluation of automatic fact-checking systems. Preliminary experiments show that FacTool, FactScore and Perplexity.ai are struggling to identify false claims, with the best F1=0.63 by this annotation solution based on GPT-4. Annotation tool, benchmark and code are available at https://github.com/yuxiaw/Factcheck-GPT.
PDF Abstract
