Large Scale Adversarial Representation Learning
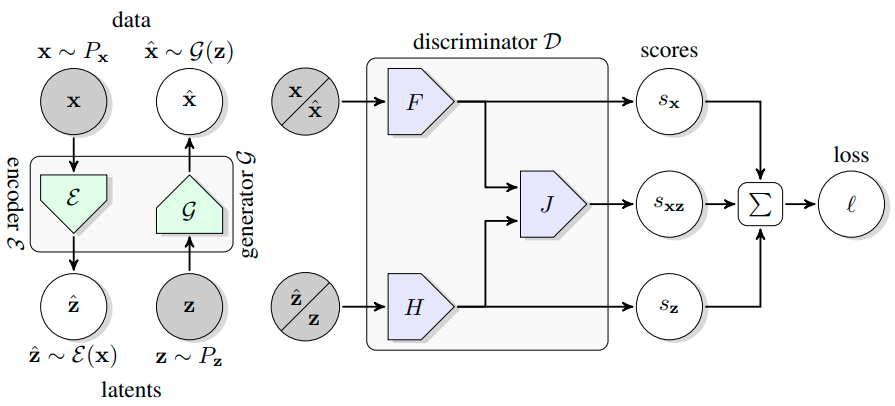
Adversarially trained generative models (GANs) have recently achieved compelling image synthesis results. But despite early successes in using GANs for unsupervised representation learning, they have since been superseded by approaches based on self-supervision. In this work we show that progress in image generation quality translates to substantially improved representation learning performance. Our approach, BigBiGAN, builds upon the state-of-the-art BigGAN model, extending it to representation learning by adding an encoder and modifying the discriminator. We extensively evaluate the representation learning and generation capabilities of these BigBiGAN models, demonstrating that these generation-based models achieve the state of the art in unsupervised representation learning on ImageNet, as well as in unconditional image generation. Pretrained BigBiGAN models -- including image generators and encoders -- are available on TensorFlow Hub (https://tfhub.dev/s?publisher=deepmind&q=bigbigan).
PDF Abstract NeurIPS 2019 PDF NeurIPS 2019 Abstract







 ImageNet
ImageNet

