ViT-DD: Multi-Task Vision Transformer for Semi-Supervised Driver Distraction Detection
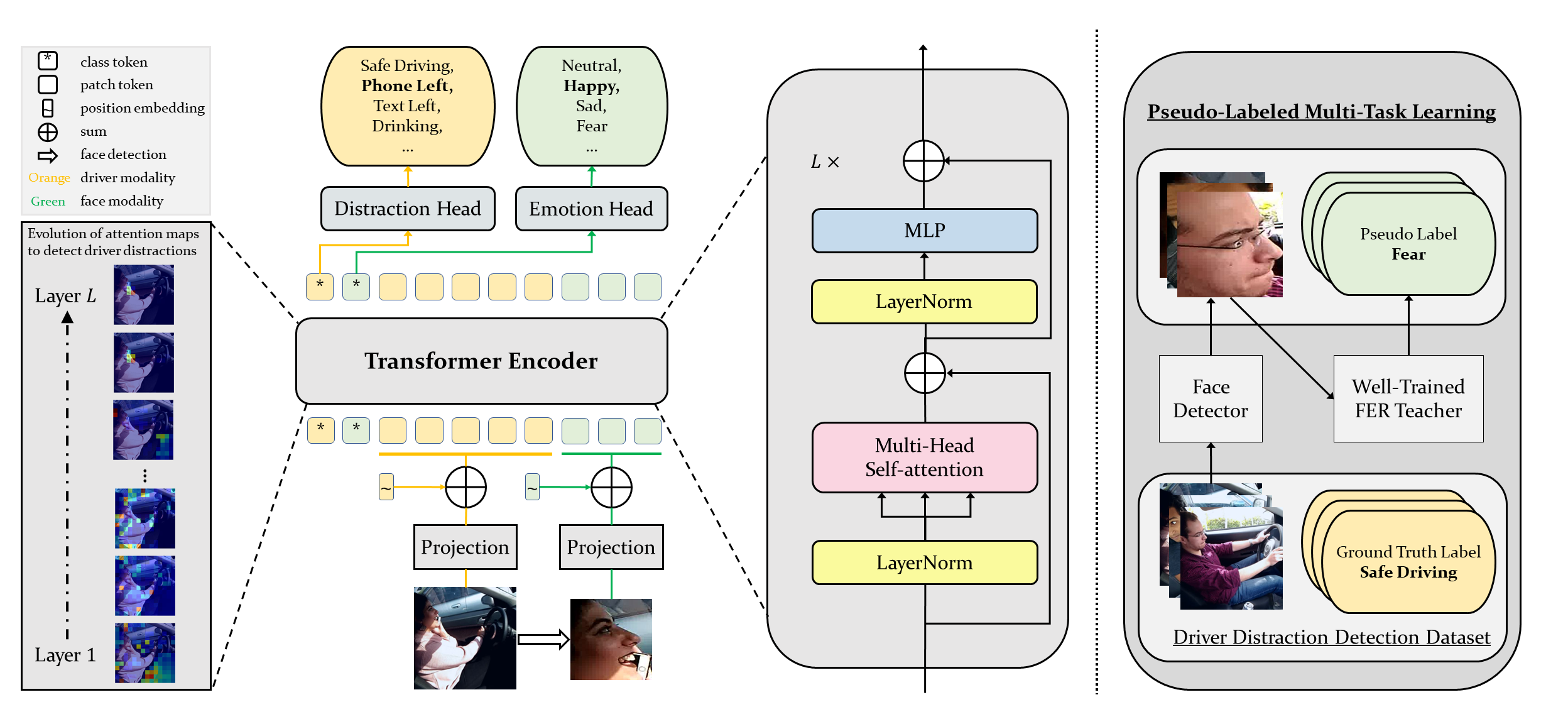
Ensuring traffic safety and mitigating accidents in modern driving is of paramount importance, and computer vision technologies have the potential to significantly contribute to this goal. This paper presents a multi-modal Vision Transformer for Driver Distraction Detection (termed ViT-DD), which incorporates inductive information from training signals related to both distraction detection and driver emotion recognition. Additionally, a self-learning algorithm is developed, allowing for the seamless integration of driver data without emotion labels into the multi-task training process of ViT-DD. Experimental results reveal that the proposed ViT-DD surpasses existing state-of-the-art methods for driver distraction detection by 6.5% and 0.9% on the SFDDD and AUCDD datasets, respectively.
PDF Abstract

 AffectNet
AffectNet
