Recycle-and-Distill: Universal Compression Strategy for Transformer-based Speech SSL Models with Attention Map Reusing and Masking Distillation
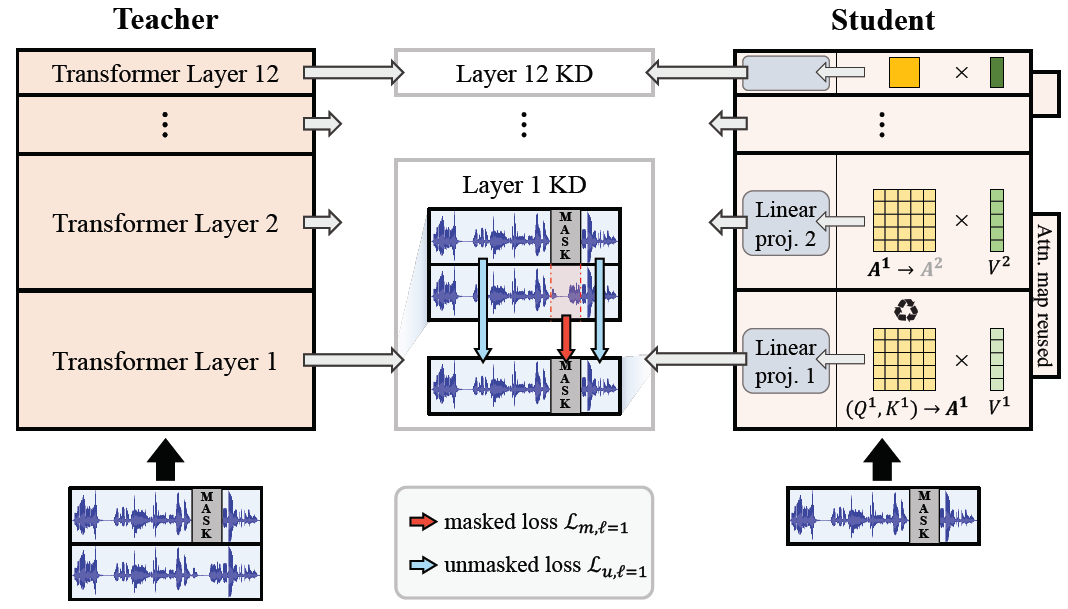
Transformer-based speech self-supervised learning (SSL) models, such as HuBERT, show surprising performance in various speech processing tasks. However, huge number of parameters in speech SSL models necessitate the compression to a more compact model for wider usage in academia or small companies. In this study, we suggest to reuse attention maps across the Transformer layers, so as to remove key and query parameters while retaining the number of layers. Furthermore, we propose a novel masking distillation strategy to improve the student model's speech representation quality. We extend the distillation loss to utilize both masked and unmasked speech frames to fully leverage the teacher model's high-quality representation. Our universal compression strategy yields the student model that achieves phoneme error rate (PER) of 7.72% and word error rate (WER) of 9.96% on the SUPERB benchmark.
PDF Abstract

 LibriSpeech
LibriSpeech
