Scaling Vision Transformers to Gigapixel Images via Hierarchical Self-Supervised Learning
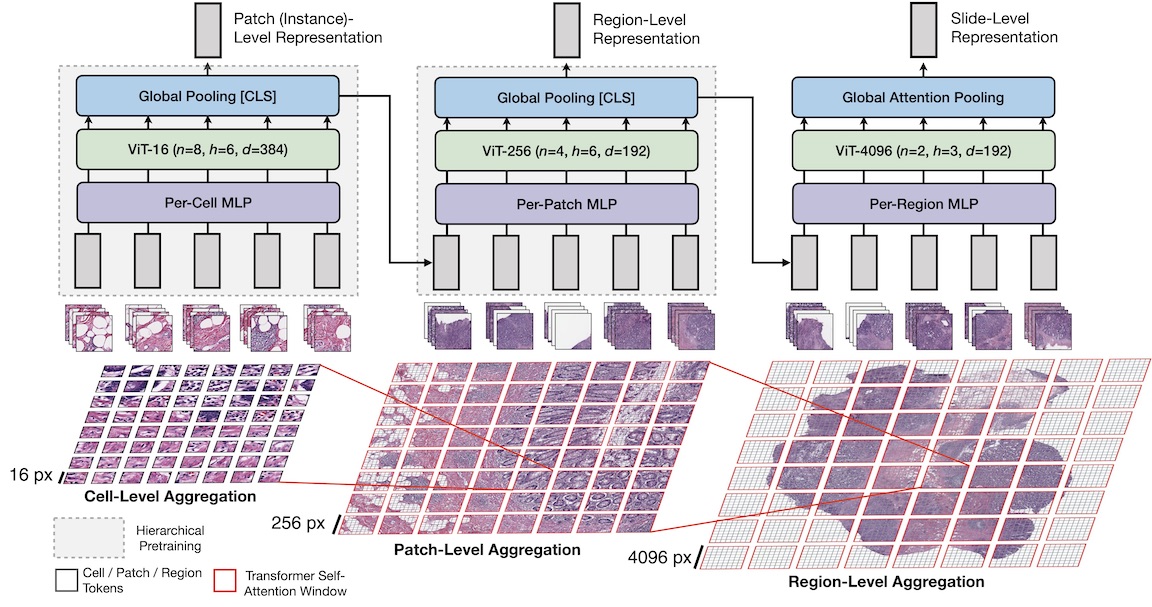
Vision Transformers (ViTs) and their multi-scale and hierarchical variations have been successful at capturing image representations but their use has been generally studied for low-resolution images (e.g. - 256x256, 384384). For gigapixel whole-slide imaging (WSI) in computational pathology, WSIs can be as large as 150000x150000 pixels at 20X magnification and exhibit a hierarchical structure of visual tokens across varying resolutions: from 16x16 images capture spatial patterns among cells, to 4096x4096 images characterizing interactions within the tissue microenvironment. We introduce a new ViT architecture called the Hierarchical Image Pyramid Transformer (HIPT), which leverages the natural hierarchical structure inherent in WSIs using two levels of self-supervised learning to learn high-resolution image representations. HIPT is pretrained across 33 cancer types using 10,678 gigapixel WSIs, 408,218 4096x4096 images, and 104M 256x256 images. We benchmark HIPT representations on 9 slide-level tasks, and demonstrate that: 1) HIPT with hierarchical pretraining outperforms current state-of-the-art methods for cancer subtyping and survival prediction, 2) self-supervised ViTs are able to model important inductive biases about the hierarchical structure of phenotypes in the tumor microenvironment.
PDF Abstract CVPR 2022 PDF CVPR 2022 Abstract


