Semantic Segmentation by Early Region Proxy
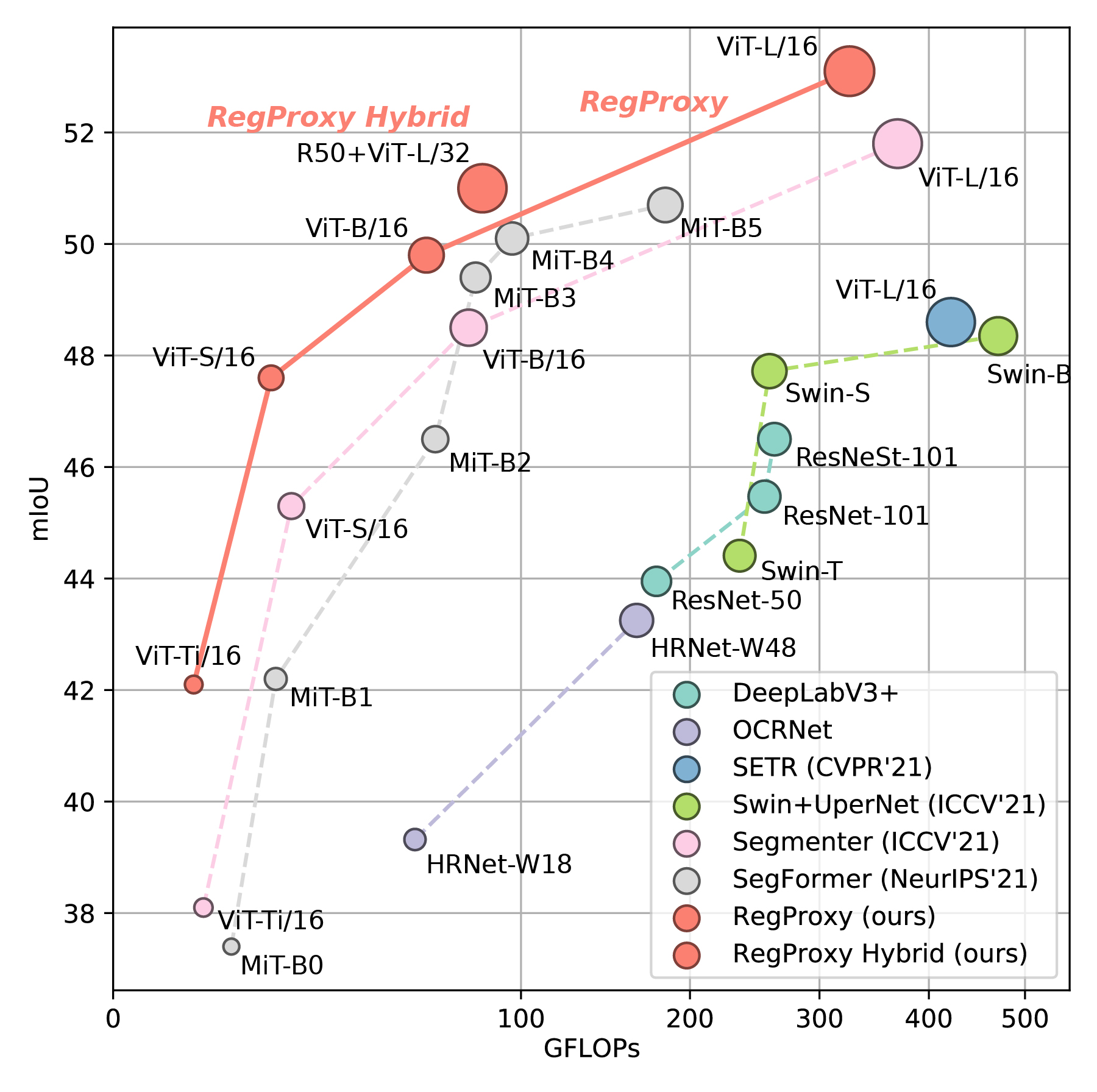
Typical vision backbones manipulate structured features. As a compromise, semantic segmentation has long been modeled as per-point prediction on dense regular grids. In this work, we present a novel and efficient modeling that starts from interpreting the image as a tessellation of learnable regions, each of which has flexible geometrics and carries homogeneous semantics. To model region-wise context, we exploit Transformer to encode regions in a sequence-to-sequence manner by applying multi-layer self-attention on the region embeddings, which serve as proxies of specific regions. Semantic segmentation is now carried out as per-region prediction on top of the encoded region embeddings using a single linear classifier, where a decoder is no longer needed. The proposed RegProxy model discards the common Cartesian feature layout and operates purely at region level. Hence, it exhibits the most competitive performance-efficiency trade-off compared with the conventional dense prediction methods. For example, on ADE20K, the small-sized RegProxy-S/16 outperforms the best CNN model using 25% parameters and 4% computation, while the largest RegProxy-L/16 achieves 52.9mIoU which outperforms the state-of-the-art by 2.1% with fewer resources. Codes and models are available at https://github.com/YiF-Zhang/RegionProxy.
PDF Abstract CVPR 2022 PDF CVPR 2022 Abstract


 ImageNet
ImageNet
 Cityscapes
Cityscapes
 ADE20K
ADE20K
 PASCAL Context
PASCAL Context
